Training a machine learning model successfully can be a challenging and time consuming task. Unlike typical software development, the results of training depend on both the training code and the input data. This can make debugging a training job a complex process, even when you’re running it on your local machine. Running code on remote infrastructure can make this task even more difficult.
Debugging code that runs in a managed cloud environment can be a tedious and error-prone process since the standard tools used to debug programs locally aren’t available in a managed environment. Also, training jobs can get stuck and stop making progress without visible logs or metrics. Interactive access to the job has the potential to make the entire debugging process significantly easier.
In this article, we introduce the interactive shell, a new tool available to users of Vertex AI custom training jobs. This feature gives you direct shell-like access to the VM that’s running your code, giving you the ability to run arbitrary commands to profile or debug issues that can’t be resolved through logs or monitoring metrics. You can also run commands using the same credentials as your training code, letting you investigate permissions issues or other problems that are not locally reproducible. Access to the interactive shell is authenticated using the same set of IAM permissions used for regular custom training jobs, providing a secure interface to the Vertex AI training environment.
Example: TensorFlow distributed training
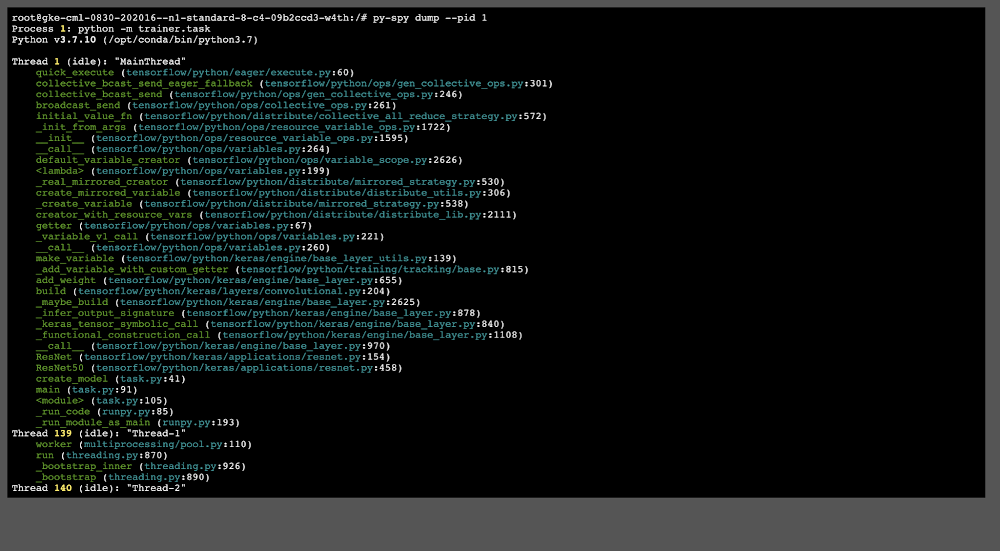
Let’s take a look at one example where using the interactive shell in Vertex AI can be useful to debug a training program. In this case, we’ll intentionally submit a job to Vertex AI training that deadlocks and stops making progress. We’ll use py-spy in the interactive shell to understand the root cause of the issue.
Vertex AI is a managed ML platform that provides a useful way to scale up your training jobs to take advantage of additional compute resources. To run your TensorFlow trainer across multiple nodes or accelerators, you can use TensorFlow’s distribution strategy API, the TensorFlow module for running distributed computation. To use multiple workers, each with one or more GPUs, we’ll use tf.distribute.MultiWorkerMirroredStrategy, which uses an all-reduce algorithm to synchronize gradient updates across multiple devices.
Setting up your code
We’ll use the example from the Vertex AI Multi-Worker Training codelab. In this codelab, we train an image classification model on the Tensorflow Cassava dataset using a ResNet50 model pre-trained on Imagenet. We’ll run the training job on multiple nodes using tf.distribute.MultiWorkerMirroredStrategy.
In the codelab, we create a custom container for the training code and push it to Google Container Registry (GCR) in our GCP project.



