
Data Analytics
#da
In this blog series, a companion to our white paper, we’re exploring different types of data-driven organizations. In our previous blogs of this series, a data scientist driven organization seeks to maximize value derived from data by making it highly accessible and discoverable, while also applying robust governance and operational rigor to rapidly deploy ML models. A data engineering driven organization typically provides 3 categories of data workers, with data engineers acting as the stewards of data that is used to generate analyses by an analytics team, for consumption by business users. Many of the same design decisions and technologies come into play between these organization types, but the social and organizational aspects are different.
Regardless of the composition of your organization’s data workers and their exact roles, you’re probably facing a lot of the same challenges. Some of these may be familiar to you:
-
Your data is stale, noisy, or otherwise untrustworthy
-
You need reliable data quickly in order to make rapid business decisions, but integrating new data sources is time consuming and costly
-
You struggle to find a balance among reducing risk, increasing profitability, and innovation
-
A lot of your time is spent on pulling reports for regulatory compliance instead of generating insights for the business
Some of these challenges are more profound for companies in a highly regulated industry, but data freshness, time to insights, reduction of risk, and innovation are key to any company. The common thread is the tremendous pressure to transform insights into business value, as fast as possible. Your customers are demanding accurate and faster interactions driven by data. As a result, your organization needs to sharpen your data analytics capabilities to stay competitive.
At the same time, technology is evolving around you, creating a skill gap with the introduction of new technologies such as data lakes or data processing frameworks such as Spark. These technologies are powerful but require programming skills in languages such as Java or Scala. They present a radically different paradigm to the classic SQL declarative approach. There is a delicate balance of data workers within a company, and more traditional data architectures require very specific technical skills. Any new technology stack that disrupts this balance requires a redistribution of technical skills or a different ratio of engineering resources to other data workers. It’s often easier for a department head to justify an additional person on the team with new skills than it is to make broad sweeping changes to a central IT department, and as a result, evolution and new skill sets only occur in pockets of the org chart.
So, why doesn’t technology adapt to your needs?
The rise and fall of technologies such as Hadoop has revealed the elephant in the room (pun intended). Technology needs to fit into your culture and needs to build on your capabilities. This allows you to be more productive, reflect business needs, and preserve your subject matter expertise. You don’t need to become an engineering driven organization to leverage new technology!
We’re going to explore how a platform like BigQuery, a pioneer in the concept of a cloud structured data lake, can provide a scalable processing engine and storage layer that can deal with the new and diverse data sources, via a familiar, SQL-based user interface.
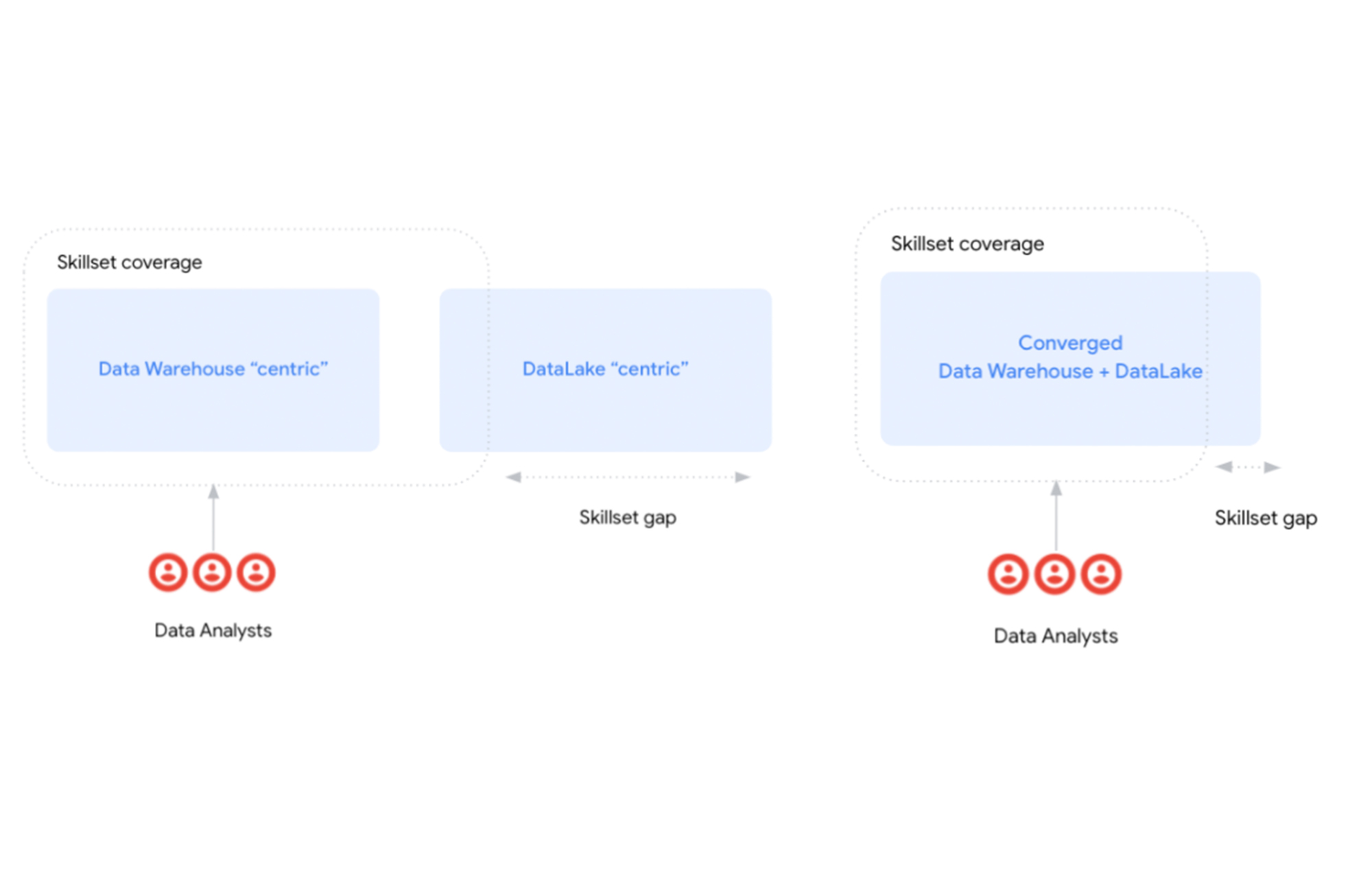
How do you build the “data-driven” agenda for data analyst driven organizations?
Before discussing the main levers to pull for the transformation, let’s define what we mean by a data analyst driven organization. It should be noted that whether an organization is analyst driven is not a binary concept, but instead presents a wide range of overlapping characteristics:
-
Mature industry. At the macro level, these organizations are red-brick established names with legacy systems. Generally, the industry in which they operate can be considered mature and stable.
-
Competition from emerging digital natives. From a competitive standpoint, in addition to other similar organizations, there are also emerging digital organizations (for instance. fintech) that aim to capture the fastest growing digital areas and customer segments that have the highest potential.
-
EDW + Batch ETL. Technically speaking, the central information piece comes in the form of an enterprise data warehouse (EDW) built over the years with a high level of technical debt and legacy technology. The transformation of the data within the data warehouse is carried out through scheduled ETL (Extract Transform Load) processes such as nightly batches. This batch process adds to the latency of serving the data.
-
Business Intelligence. Most data workers in the organization are used to answering business questions by launching SQL queries against a centralized data warehouse, creating reports and dashboard using BI tools. In addition, spreadsheets are used to access similar data. Thus, the internal talent pool is most comfortable with SQL, BI tools, and spreadsheets.
Narrowing the focus to the data department, the main personas and processes in these types of organizations can be generalized as follows:
-
Data analysts, focused on receiving, understanding, and serving the requests coming from the business and making sense of the relevant data.
-
Business analysts put the information into a context and act upon the analytical insights.
-
Data Engineers, focused on the downstream data pipeline and the first phases of data transformation, such as, loading and integration of new sources. In addition, managing the data governance and data quality processes.
Finally and given its relevance, it is also worth digging deeper on what we understand by a data analyst. As a data analyst, your goal is to meet the information needs of your organization. You are responsible for the logical design and maintenance of the data itself. Some of the tasks may include creating layout and design of tables to meet the business processes, reorganization, and transformation of sources. In addition, you’re also responsible for the generation of reports and insights that effectively communicate trends, patterns, or predictions that the business asks for.
Going back to our original question of how we can build the mission for the data analyst driven organizations, the answer is: using, and expanding the experience and skill-set of the data analyst community.
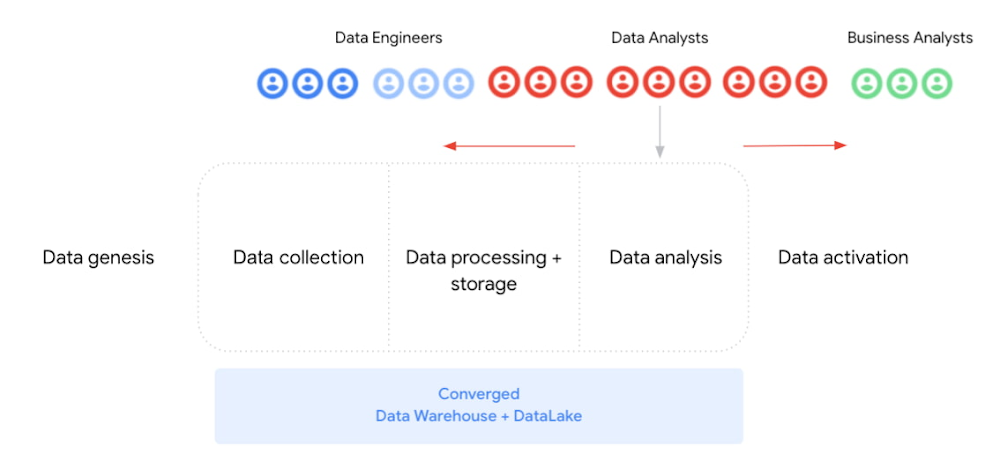
On one hand, we promote the trend of data analysts making steps into the business side. As discussed earlier, data analysts bring in valuable knowledge with a deep knowledge of business domains and with sufficient technical skills to analyze data regardless of its volume or size.
Cloud-based data warehouses and serverless technologies such as BigQuery contribute to this expansion of responsibilities toward right (as highlighted in Figure 3). In a way, allowing data analysts to focus on adding value rather than wasting time and effort in administrative / technical management tasks. Furthermore, you can now invest that extra time going deeper into the business without being limited by the volume or type of data that the storage system supports.
On the other hand, new data processing paradigms enable a movement in the opposite direction for the data analysts area of responsibility. You can use SQL as the fundamental query tool for data analysis, but now you can also use it for data processing/transformation. In the process, data analysts are able to take on some of the data engineering’s work: data integration and enrichment.
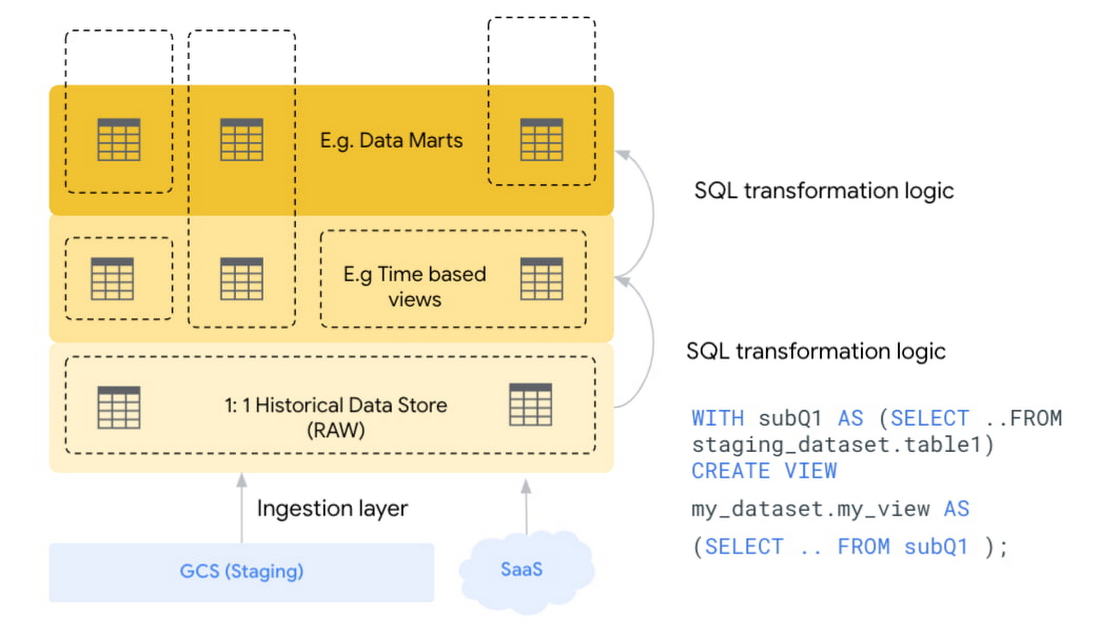
Data analyst driven organizations embrace the concept of ELT (Extract-Load-Transform) rather than the traditional ETL (Extract-Transform-Load). The main difference is the common data processing tasks are handled after the data is loaded to the data warehouse. ELT makes extensive use of SQL logic to enhance, cleanse, normalize, refine, and integrate data and make it ready for analysis. There are several benefits of such an approach: it reduces time to act, data is loaded immediately, and it is made available to multiple users concurrently.
A robust, transformational, actionable architecture for data analyst driven organizations
So far we have talked briefly about the technological innovations that enable the data transformation, in this section we are going to focus on a more detailed description of these building blocks.
To define a high-level architecture, we are going to start by defining the first principles from which we derive the components and interrelationships. It goes without saying that a real organization must adapt these principles and therefore the architecture decisions to its reality and existing investments.
-
Principle #1: SQL as the analytics “lingua franca”
-
Technology should adapt to the current organizational culture. Prioritize components that offer a SQL interface, no matter where they are in the data processing pipeline.
Principle #2: Rise of the Structured Data Lake
-
Information systems infrastructure and its data should converge, to help expand the possibilities of analytical processing on new and diverse data sources. This may mean merging a traditional data warehouse with a data lake to eliminate silos.
Principle #3: Assume and plan for “data/schema liquidity”
-
Storage is cheap, so your organization no longer needs to impose rigid rules regarding data structures before data arrives. Moving away from a schema-on-write to schema-on-read model enables real-time access to data. Data can be kept in its raw form and then transformed into the schema that will be useful. In addition, the data platform can manage the process of keeping these copies in sync (for instance using materialized views, CDC, etc.). So do not be afraid to maintain several copies of the same data asset,
Combining these principles we can define a high-level architecture like the one shown in the following diagram.
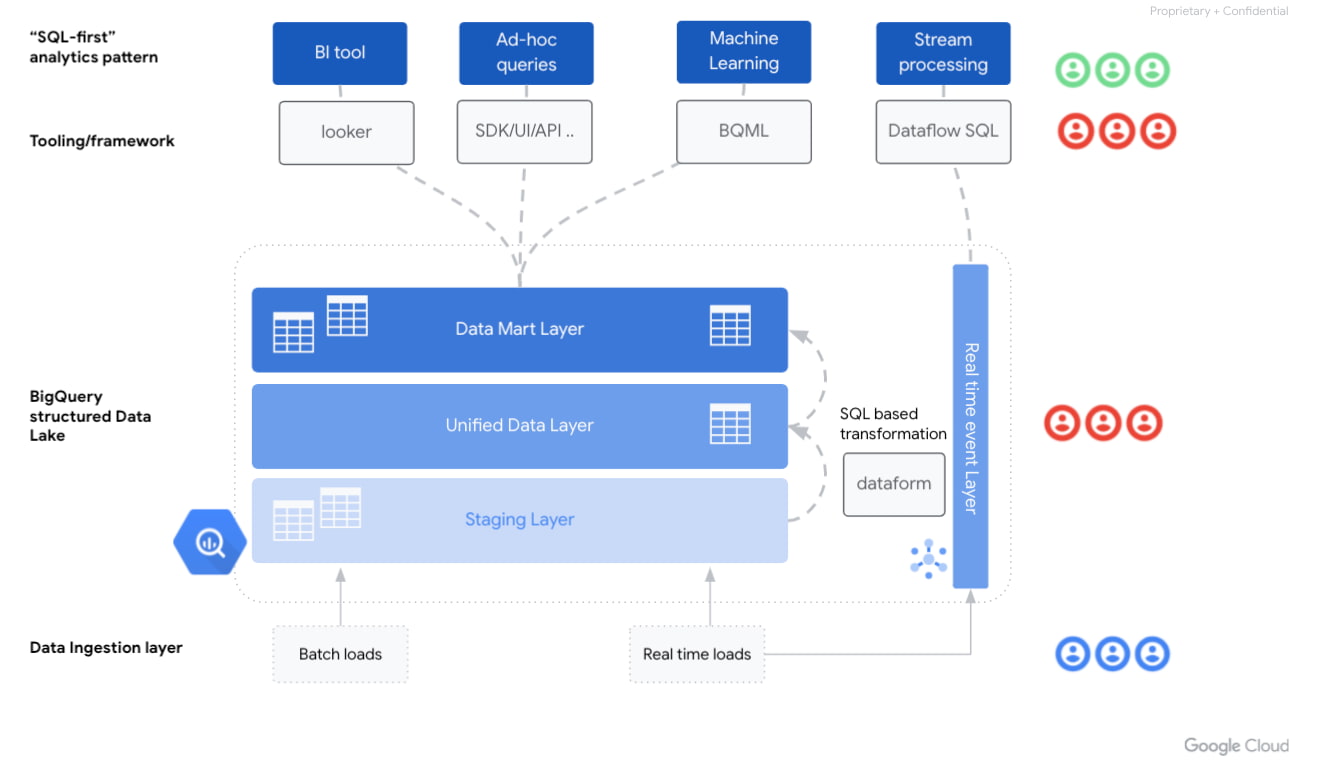
What components do we observe in the informational architecture of this type of organization?
First of all, a modern data platform should support an increasing number of data analysis patterns:
-
the “classic” Business Intelligence workloads with tools such as Looker,
-
a SQL based ad hoc analytics interface allowing management of data pipelines through ELT
-
Enabling data science use cases with machine learning techniques
-
real-time event processing
Although the first two patterns are quite close to the traditional SQL data warehousing world, the last two present innovations in the form of SQL abstractions to more advanced analytical patterns. In the realm of machine learning, for example, we have BigQuery ML, which lets us execute machine learning models in BigQuery using standard SQL queries. And Dataflow SQL streaming extensions enable aggregating data streams with the underlying Dataflow sources like Pub/Sub or Kafka. Think for a moment the world of possibilities that technology enables without the need to invest in new profiles and/or roles.
For a data analysts driven organization, the data preparation and transformation challenge is a clear and loud message in choice between ELT vs ETL. Use ELT wherever possible; the significant difference with this new paradigm is where the data is transformed – inside the Structured Data Lake and by using SQL.
It is possible to transform data with SQL without sacrificing functionalities offered by extensive data integration suites. But how do you handle scheduling, dependency management, data quality, or operations monitoring? Products such as dbt or BigQuery Dataform bring a software engineering approach to data modeling and building data workflows. At the same time, they allow non-programmers to carry out robust data transformations.
Modelling techniques such as Data Vault 2.0 are making a comeback due to the power of ELT in the new Cloud driven data warehouses. Therefore, It is important to note that the logical distribution of the data remains unaltered following the classical patterns such as the Immon or Kimball reference architectures. [1] [2]
In data analyst driven organizations, data engineering teams generally control extraction of data from source systems. While it can be made easier through the use of SQL-based tools, enabling data analysts to do some of that work, there is still a need for a strong data engineering team. There are batch jobs that would still require creating data pipelines that would be more suitable for ETL. For example, bringing data from a mainframe to a data warehouse would require additional processing steps: data types need to be mapped, COBOL books need to be converted, and so on. In addition, for use cases like real time analytics, the data engineering teams will configure the streaming data sources such as Pub/Sub or Kafka topics. The way that you deal with generic tasks is still the same — they can be written as generic ETL pipelines and then reconfigured by the analysts. For example, applying data quality validation checks from various source datasets to the target environment. The main point is that with the power of cloud data warehouses, it is now possible to use ELT instead of traditional ETL tasks. However, as described above there are use cases such as data quality applications that we need ETL.
In summary
In this article we have identified the data analyst driven organization and reviewed the challenges faced by them. We have seen how it is possible to build a transformation plan around one of your most valuable assets: data analysts. We have also reviewed the main components that appear in a modern, scalable informational architecture needed to efficiently use such an organization. Data analysts’ responsibilities are expanding to advanced data engineering tasks such as automatic learning or real-time event processing. All of these are still possible through our familiar and beloved favorite interface: SQL. To get started with the Google Cloud data ecosystem, please feel free to contact us or start a free trial.




