
Real-time analytics made easy with Cloud Spanner federated queries with BigQuery
August 27, 2021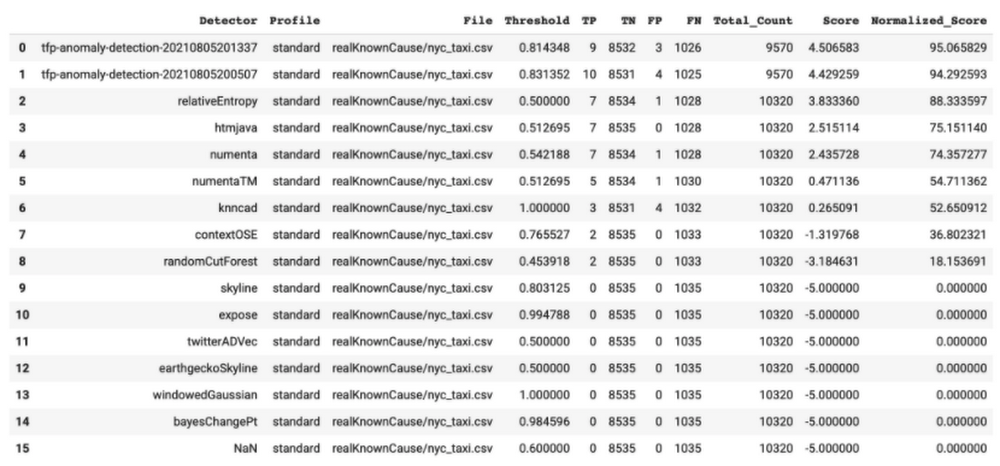
Anomaly detection with TensorFlow Probability and Vertex AI
August 27, 2021
Developers & Practitioners
Cloud Spanner is GCP’s native and distributed Online Transaction Processing System (OLTP). Due to its distributed nature, it can scale horizontally and therefore is suitable for workloads with very high throughputs containing large volumes of data. This invites a huge opportunity to do analytics on top of it. Thanks to Cloud Spanner BigQuery Federation, you can now easily fetch Cloud Spanner data into BigQuery for analytics.
In this post, you will learn how to efficiently use this feature to replicate large tables with high throughput (lots of inserts or updates written per second), with low to medium replication lag.
ELT process optimizations
Setting up an efficient Extract Load and Transform (ELT) to fetch data from Cloud Spanner to BigQuery is the key for low replication lag. After performing an initial full load, you will need to set up incremental loads. For large tables in Cloud Spanner, refreshing full data every time can be slow and costly. Therefore it is more efficient to extract only new changes and merge with existing data in BigQuery.
Designing Cloud Spanner for incremental data
Taking an example table schema such as below:
CREATE TABLE Singers (SingerId String NOT NULL,FirstName STRING(1024),LastName STRING(1024),SingerInfo BYTES(MAX),) PRIMARY KEY (SingerId);
In order to identify incremental changes, you will need to add a commit timestamp column (say lastUpdateTimePENDING_COMMIT_TIMESTAMP(), so that Cloud Spanner updates the corresponding field post commit.
To efficiently read the rows changed after a certain timestamp you will need to create an index. Since indexes on monotonically increasing values can cause hotspots you will need to add another column (say shardid) and create a composite index using (shardid, lastUpdatedTime).
Updated schema would look as below:
CREATE TABLE Singers (SingerId String NOT NULL,FirstName STRING(1024),LastName STRING(1024),SingerInfo BYTES(MAX),LastUpdateTime TIMESTAMP NOT NULL OPTIONS (allow_commit_timestamp = true),ShardId INT64 AS (MOD(FARM_FINGERPRINT(SingerId), 19)) STORED,) PRIMARY KEY(SingerId);CREATE NULL_FILTERED INDEX Idx_singers_shard_LastModified ON Singers(ShardId, LastUpdateTime DESC);
In the above example, I have added LastUpdateTime as a commit timestamp column. Also added ShardId as a generated column which will produce values in range of -18 to +18. This helps in avoiding hotspots when indexing timestamp by creating composite an index on (ShardId, LastUpdateTime).
Further you can make it a NULL FILTERED index to keep it light. You can periodically update LastUpdateTime as null for old records. Read here for a more detailed solution.
Now to query incremental changes from the table SQL query will be as follows:
select * from Singers@{FORCE_INDEX=Idx_singers_shard_LastModified} where shardid between -18 and 18 and LastUpdateTime > '2021-07-25 00:00:00.0Z'
Above sql query reads data from all shards as well as filters on LastUpdateTime. Therefore using the index to optimize reading speed from large tables.
Initial loading of data into BigQuery
Loading data for the first time is likely to read the entire table in Cloud Spanner and send results into BigQuery. Therefore you should create a connection with the “Read Data in Parallel” option.
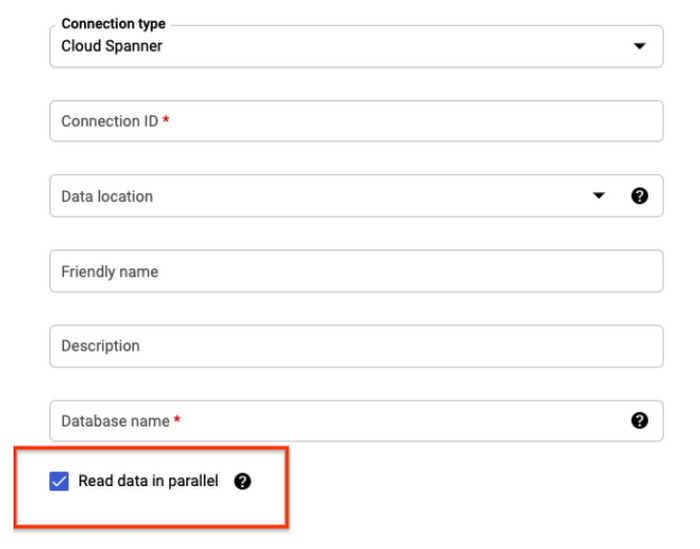
Below is an example sql query to do the initial load.
CREATE TABLE dataset.singers asselect * from EXTERNAL_QUERY("myproject.us.my_spanner_conn","SELECT * FROM singers")
Incrementally loading data into BigQuery
Update the connection (or create new connection) with “Read data in parallel” unchecked.

This is because (at the time of writing), Spanner queries using indices are not root partitionable and the result cannot be read in parallel. This might get changed in future.
After getting incremental data from Cloud Spanner it should be stored into a staging table in BigQuery, thus completing the Extract and Load part of (ELT). Finally you will need to write a Merge statement to consolidate incremental data into a BigQuery table.
Thanks to BigQuery’s scripting all of this ELT can be combined into a single script as below and further it can be configured as scheduled query.
DECLARE lastRead TimeStamp DEFAULT (select max(LastUpdateTime) LastUpdate from dataset.singers);EXECUTE IMMEDIATE CONCAT("CREATE TABLE dataset.singers_stg as select * from EXTERNAL_QUERY("myproject.us.my_spanner_conn","SELECT * FROM singers where shardid between -18 and 18 and LastUpdateTime > '",lastRead,"' ")");MERGE INTO dataset.singers sUSING dataset.singers_stg nON s.singerid = n.singeridWHEN MATCHED THENUPDATE SET firstname = n.firstname, lastname = n.lastname, SingerInfo = n.SingerInfo,LastUpdateTime = n.LastUpdateTime, shardid = n.shardidWHEN NOT MATCHED THENINSERT (singerid, firstname, lastname, singerinfo, lastupdatetime, shardid)values (singerid, firstname, lastname, singerinfo, lastupdatetime, shardid);DROP TABLE dataset.singers_stg;
Above script finds last time bigquery was updated for that table. It constructs a SQL Query to fetch any incremental data post last fetch and store it as a staging table. Then merge new data into bigquery table and finally delete the staging table.
Explicit dropping of table ensures that two parallel executions of above script will fail. This is important so that if there is a sudden surge then no data shall be missed.
Other considerations
Creating table partitions in BigQuery
It is common to create table partitions and clustering based on your reads / analytics requirements. However, this can lead to a low merge performance. You should make use of BigQuery partitioning and clustering in such cases.
Clustering can improve match performance, therefore you can add clustering on the PK of the table. Merging data rewrites entire partitions, having partition filters can limit volume of data rewritten.
Handling deleted rows
Above solution will skip over deleted rows, which might be acceptable for many use-cases. However if you need to track the deletes then the application will need to implement soft deletes like add a column isDeleted = true/false. Data from Cloud Spanner should be hard deleted after some delay so that changes are synchronized into BigQuery first.
During merge operation in bigquery you can conditionally delete based on the above flag.
What’s next
In this article you learned about how to replicate data from Cloud Spanner to BigQuery. If you want to test this in action, use Measure Cloud Spanner performance using JMeter for a step by step guide on generating sample data on Cloud Spanner for your workload schema.

