Developers & Practitioners
In today’s post, we’ll walk through how to easily create optimal machine learning models with BigQuery ML’s recently launched automated hyperparameter tuning. You can also register for our free training on August 19 to gain more experience with hyperparameter tuning and get your questions answered by Google experts. Can’t attend the training live? You can watch it on-demand after August 19.
Without this feature, users have to manually tune hyperparameters by running multiple training jobs and comparing the results. The efforts might not even work without knowing the good candidates to try out.
With a single extra line of SQL code, users can tune a model and have BigQuery ML automatically find the optimal hyperparameters. This enables data scientists to spend less time manually iterating hyperparameters and more time focusing on unlocking insights from data. This hyperparameter tuning feature is made possible in BigQuery ML by using Vertex Vizier behind-the-scenes. Vizier was created by Google research and is commonly used for hyperparameter tuning at Google.
BigQuery ML hyperparameter tuning helps data practitioners by:
- Optimizing model performance with one extra line of code to automatically tune hyperparameters, as well as customizing the search space
- Reducing manual time spent trying out different hyperparameters
- Leveraging transfer learning from past hyperparameter-tuned models to improve convergence of new models
How do you create a model using Hyperparameter Tuning?
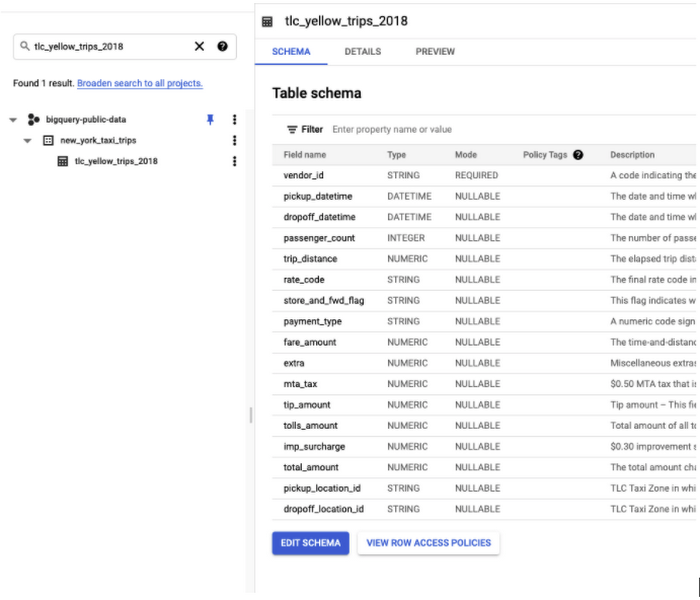
You can follow along in the code below by first bringing the relevant data to your BigQuery project. We’ll be using the first 100K rows of data from New York taxi trips that is part of the BigQuery public datasets to predict the tip amount based on various features, as shown in the schema below:
First create a dataset, bqml_tutorial in the United States (US) multiregional location, then run:
CREATE TABLE `bqml_tutorial.taxi_tip_input` ASSELECT* EXCEPT(tip_amount), tip_amount AS labelFROM`bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2018`WHEREtip_amount IS NOT NULLLIMIT 100000
Without hyperparameter tuning, the model below uses the default hyperparameters, which may very likely not be ideal. The responsibility falls on data scientists to train multiple models with different hyperparameters, and compare evaluation metrics across all the models. This can be a time-consuming process and it can become difficult to manage all the models. In the example below, you can train a linear regression model, using the default hyperparameters, to try to predict taxi fares.
#without hyperparameter tuningCREATE MODEL `bqml_tutorial.without_hp_taxi_tip_model`OPTIONS(model_type='linear_reg',input_label_cols=['label']) ASSELECT *FROM`bqml_tutorial.taxi_tip_input`
With hyperparameter tuning (triggered by specifying NUM_TRIALS), BigQuery ML will automatically try to optimize the relevant hyperparameters across a user-specified number of trials (NUM_TRIALS). The hyperparameters that it will try to tune can be found in this helpful chart.
#with hyperparameter tuningCREATE MODEL `bqml_tutorial.hp_taxi_tip_model`OPTIONS(model_type='linear_reg',input_label_cols=['label'],num_trials=20,max_parallel_trials=2) ASSELECT *FROM`bqml_tutorial.taxi_tip_input`
In the example above, with NUM_TRIALS=20, starting with the default hyperparameters, BigQuery ML will try to train model after model while intelligently using different hyperparameter values — in this case, l1_reg and l2_reg as described here. Before training begins, the dataset will be split into three parts1: training/evaluation/test. The trial hyperparameter suggestions are calculated based upon the evaluation data metrics. At the end of each trial training, the test set is used to evaluate the trial and record its metrics in the model. Using an unseen test set ensures the objectivity of the test metric reported at the end of tuning.
The dataset is split into 3-ways by default when hyperparameter tuning is enabled. The user can choose to split the data in other ways as described in the documentation here.
We also set max_parallel_trials=2 in order to accelerate the tuning process. With 2 parallel trials running at any time, the whole tuning should take roughly as long as 10 serial training jobs instead of 20.
Inspecting the trials
How do you inspect the exact hyperparameters used at each trial? You can use ML.TRIAL_INFO to inspect each of the trials when training a model with hyperparameter tuning.
Tip: You can use ML.TRIAL_INFO even while your models are still training.
SELECT *FROMML.TRIAL_INFO(MODEL `bqml_tutorial.hp_taxi_tip_model`)
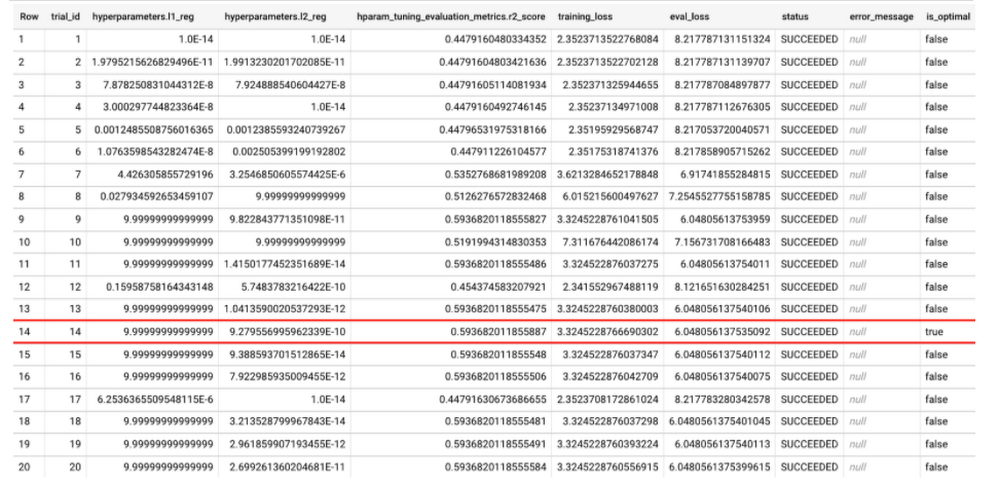
In the screenshot above, ML.TRIAL_INFO shows one trial per row, with the exact hyperparameter values used in each trial. The results of the query above indicate that the 14th trial is the optimal trial, as indicated by the is_optimal column. Trial 14 is optimal here because the hparam_tuning_evaluation_metrics.r2_score — which is R2 score for the evaluation set — is the highest. The R2 score improved impressively from 0.448 to 0.593 with hyperparameter tuning!
Note that this model’s hyperparameters were tuned just by using num_trials and max_parallel_trials, and BigQuery ML searches through the default hyperparameters and default search spaces as described in the documentation here. When default hyperparameter search spaces are used to train the model, the first trial (TRIAL_ID=1) will always use default values for each of the default hyperparameters for the model type LINEAR_REG. This is to help ensure that the overall performance of the model is no worse than a non-hyperparameter tuned model.
Evaluating your model
How well does each trial perform on the test set? You can use ML.EVALUATE, which returns a row for every trial along with the corresponding evaluation metrics for that model.
SELECT *FROMML.EVALUATE(MODEL `bqml_tutorial.hp_taxi_tip_model`)
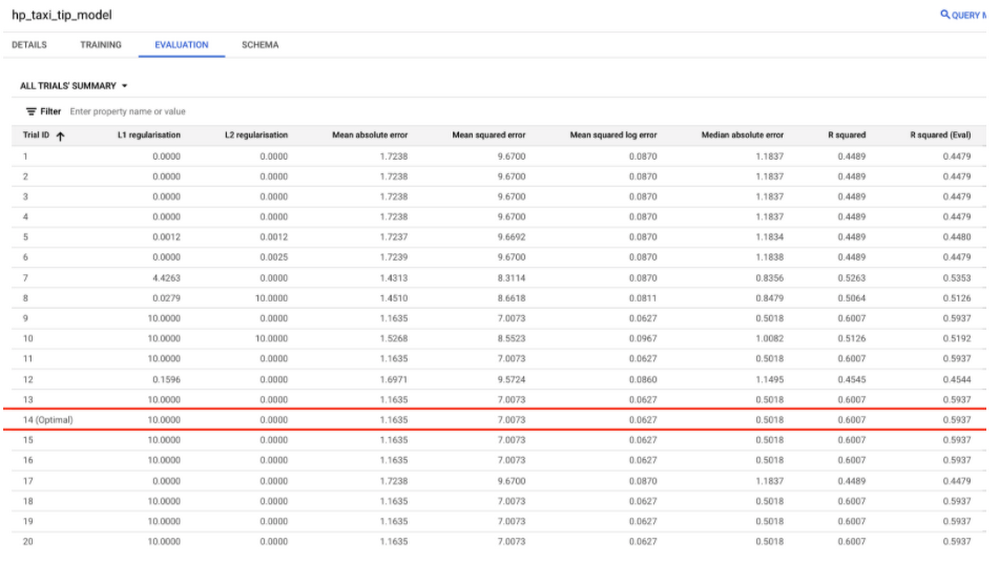
In the screenshot above, the columns “R squared” and “R squared (Eval)” correspond to the evaluation metrics for the test and evaluation set, respectively. For more details, see the data split documentation here.
Making predictions with your hyperparameter-tuned model
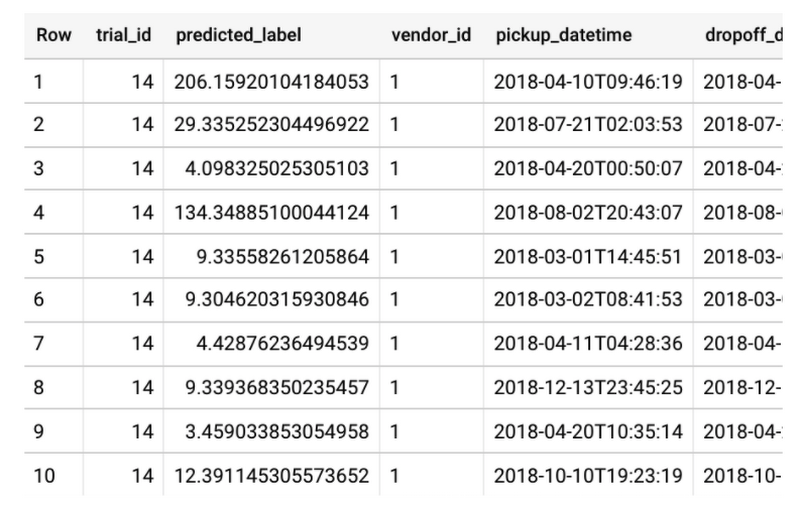
How does BigQuery ML select which trial to use to make predictions? ML.PREDICT will use the optimal trial by default and also returns which trial_id was used to make the prediction. You can also specify which trial to use by following the instructions.
SELECT*FROMML.PREDICT(MODEL `bqml_tutorial.hp_taxi_tip_model`,(SELECT*FROM`bqml_tutorial.taxi_tip_input`LIMIT 10))
Customizing the search space
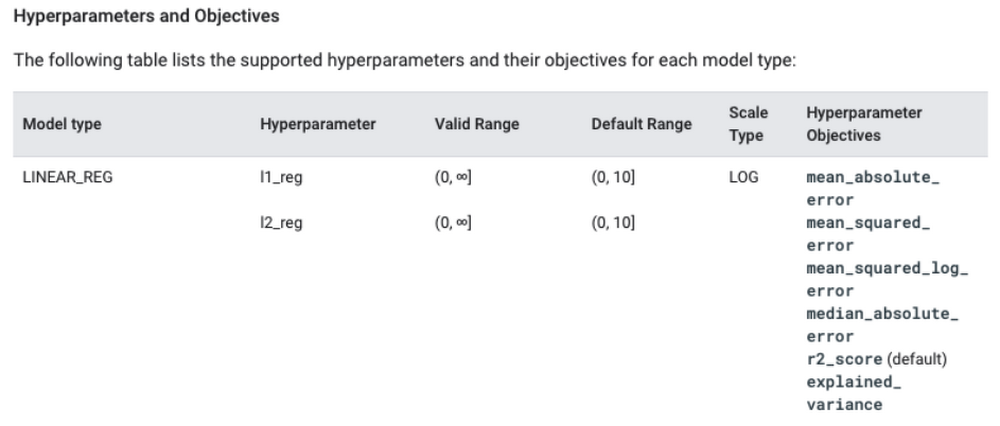
There may be times where you want to select certain hyperparameters to optimize or change the default search space per hyperparameter. To find the default range for each hyperparameter, you can explore the Hyperparameters and Objectives section of the documentation.
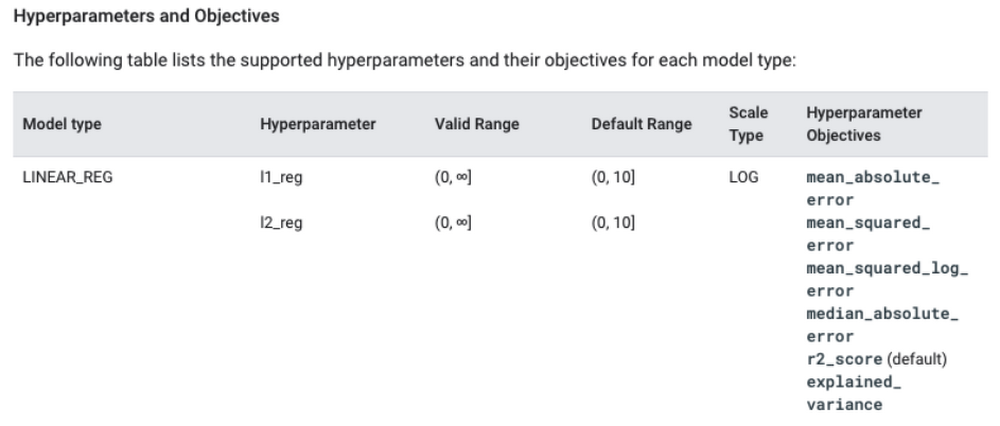
For LINEAR_REG, you can see the feasible range for each hyperparameter. Using the documentation as reference, you can create your own customized CREATE MODEL statement:
#with hyperparameter tuning, using custom HPs and custom objectiveCREATE MODEL `bqml_tutorial.hp_taxi_tip_model`OPTIONS(model_type='linear_reg',input_label_cols=['label'],num_trials=20,max_parallel_trials=2,l1_reg=HPARAM_RANGE(0, 0.5),HPARAM_TUNING_OBJECTIVES='mean_squared_errror') ASSELECT *FROM`bqml_tutorial.taxi_tip_input`
Transfer learning from previous runs
If this isn’t enough, hyperparameter tuning in BigQuery with Vertex Vizier running behind the scenes means you also get the added benefit of transfer learning between models that you train, as described here.
How many trials do I need to tune a model?
The rule of thumb is at least 10 * the number of hyperparameters, as described here (assuming no parallel trials). For example, LINEAR_REG will tune 2 hyperparameters by default, and so we recommend using NUM_TRIALS=20.
Pricing
The cost of hyperparameter tuning training is the sum of all executed trials costs, which means that if you train a model with 20 trials, the billing would be equal to the total cost across all 20 trials. The pricing of each trial is consistent with the existing BigQuery ML pricing model.
Note: Please be aware that the costs are likely going to be much higher than training one model at a time.
Exporting hyperparameter-tuned models out of BigQuery ML
If you’re looking to use your hyperparameter-tuned model outside of BigQuery, you can export your model to Google Cloud Storage, which you can then use to, for example, host in a Vertex AI Endpoint for online predictions.
EXPORT MODEL`bqml_tutorial.hp_taxi_tip_model`OPTIONS(URI = 'gs://my-bucket/linear_reg')
Summary
With automated hyperparameter tuning in BigQuery ML, it’s as simple as adding one extra line of code (NUM_TRIALS) to easily improve model performance! Ready to get more experience with hyperparameter tuning or have questions you’d like to ask? Sign up here for our no-cost August 19 training.



