
Get in sync: Consistent Kubernetes with new Anthos Config Management features
August 3, 2021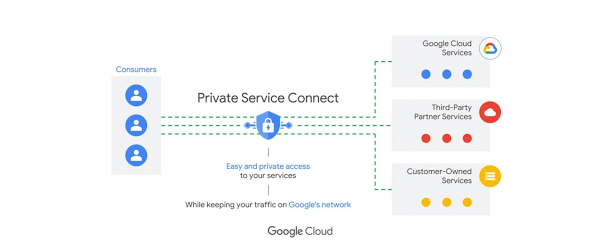
Consume services faster, privately and securely – Private Service Connect now in GA
August 4, 2021
The architecture covers three phases of generating context-driven ML predictions, including:
ML Development: Designing and building the ML models and pipeline
Vertex Notebooks are used as data science environments for experimentation and prototyping. Notebooks are also used to implement model training, scoring components, and pipelines. The source code is version controlled in Github. A continuous integration (CI) pipeline is set up to automatically run unit tests, build pipeline components, and store the container images to Cloud Container Registry.
ML Training: Large-scale training and storing of ML models
The training pipeline is executed on Vertex Pipelines. In essence, the pipeline trains the model using new training data extracted from BigQuery and produces a trained, validated contextual bandit model stored in the model registry. In our system, the model registry is a curated Cloud Storage.
The training pipeline uses Dataflow for large scale data extraction, validation, processing, and model evaluation, and Vertex Training for large-scale distributed training of the model. AI Platform Pipelines also stores artifacts, the output of training models, produced by the various pipeline steps to Cloud Storage. Information about these artifacts are then stored in an ML metadata database in Cloud SQL. To learn more about how to build a Continuous Training Pipeline, read the documentation guide.
ML Serving: Deploying new algorithms and experiments in production
The training pipeline uses batch prediction to generate many predictions at once using AI Platform Pipelines, allowing Digitec Galaxus to score large data sets. Once the predictions are produced, they are stored in Cloud Datastore for consumption. The pipeline uses the most recent contextual bandit model in the model registry to evaluate the inference dataset in BigQuery and give a ranked list of the best newsletters for each user, and persist it in Datastore. A Cloud Function is provided as a REST/HTTP endpoint to retrieve the precomputed predictions from Datastore.
All components of the code and architecture are modular and easy to use, which means they can be adapted and tweaked to several other use cases within the company as well.
Better newsletter predictions for millions
The newsletter prediction system was first deployed in production in February, and Digitec Galaxus has been using it to personalize millions of newsletters a week for subscribers. The results have been impressive, 50% higher than initial baseline. However, the collaboration is still ongoing to improve the results even more.
“Working at this level in direct exchange with Google’s machine learning experts is a unique opportunity for us. The use of contextual bandits in the targeting of our recommendations enables us to pursue completely new approaches in personalization by also personalizing the delivery of the respective recommender to the user. We have already achieved good results in our newsletter in initial experiments and are now working on extending the approach to the entire newsletter by including more contextual data about the bandits arms. Furthermore, as a next step, we intend to apply the system to our online store as well, in order to provide our users with an even more personalized experience. To build this scalable solution, we are using Google’s open source tools such as TFX and TF Agents, as well as Google Cloud Services such as Compute Engine, Cloud Machine Learning Engine, Kubernetes Engine and Cloud Dataflow.”–Christian Sager, Product Owner, Personalization (Digitec Galaxus)
Since the existing architecture and system is also dynamic, it will automatically adapt to new behaviours, trends, and users. As a result, Digitec Galaxus plans to re-use the same components and extend the existing system to help them improve the personalization of their homepage and other current use cases they have within the company. Beyond clicks and user engagement, the system’s flexibility also allows for future optimization of other criteria. It’s a very exciting time and we can’t wait to see what they build next!
