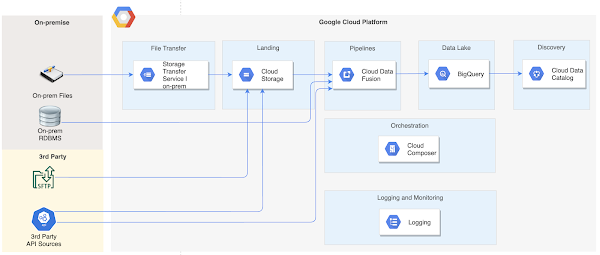
The first article in this series provided an overview of a data lake solution architecture using Data Fusion for data integration and Cloud Composer for orchestration.
In this article, I will provide an overview of the detailed solution design based on that architecture. This article assumes you have some basic understanding of GCP Data Fusion and Composer. If you are new to GCP, you can start by reading the previous article in this series to get an understanding of the different services used in the architecture before proceeding here.
Design approach
The solution design described here provides a framework to ingest a large number of source objects through the use of simple configurations. Once the framework is developed, adding new sources / objects to the data lake ingestion only requires adding new configurations for the new source.
I will publish the code for this framework in the near future. Look out for an update to this blog.
Design components
The solution design comprises 4 broad components.
- Data Fusion pipelines for data movement
- Custom pre-ingestion and post-ingestion tasks
- Configurations to provide inputs to reusable components and tasks
- Composer DAGs to execute the custom tasks and to call Data Fusion pipelines based on configurations
Let me start with a high level view of the Composer DAG that orchestrates all the parts of the solution, and then provide insight into the different pieces of the solution in the following sections.
Composer DAG structure
The Composer DAG is the workflow orchestrator. In this framework, It will broadly comprise components shown in the image below.