Cloud Spanner is a relational database management system and as such it supports the relational join operation. Joins in Spanner are complicated by the fact that all tables and indexes are sharded into splits. Every split of a table or index is managed by a specific server and in general each server is responsible for managing many splits from different tables. This sharding is managed by Spanner and it is an essential function that underpins Spanner’s industry leading scalability. But how do you join two tables when both of them are divided into multiple splits managed by multiple different machines? In this blog entry, we’ll describe distributed joins using the Distributed Cross Apply (DCA) operator.
We’ll use the following schema and query to illustrate:
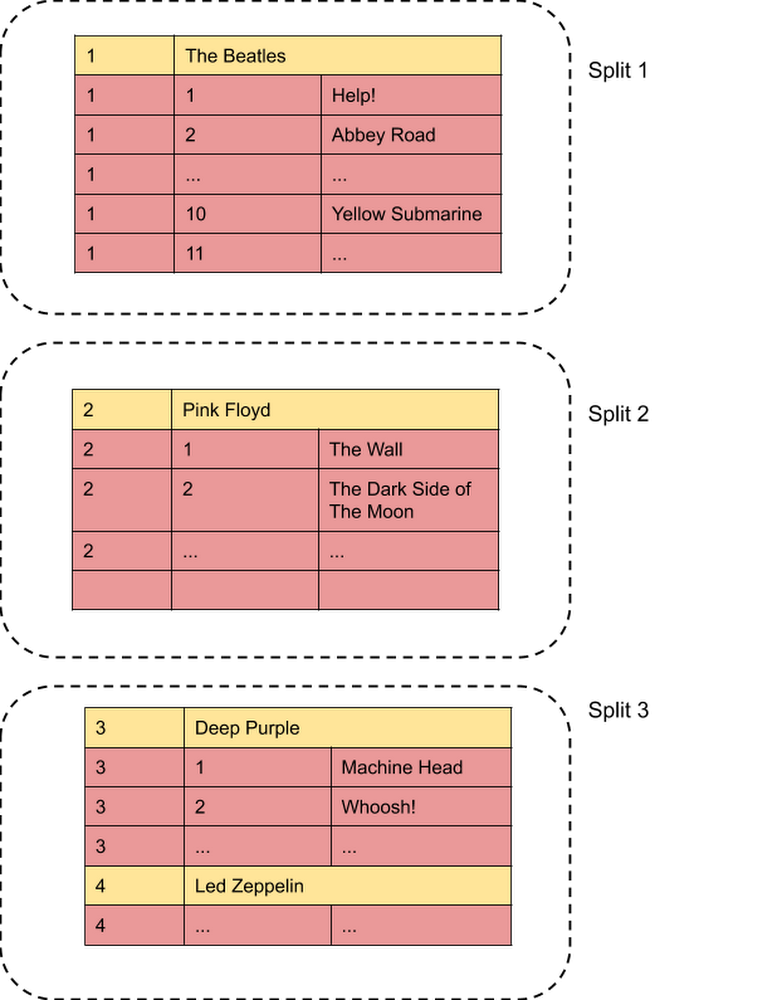
If a table is not interleaved in another table then its primary key is also its range sharding key. Therefore the sharding key of the Albums table is (SingerId, AlbumId). The following figure shows the query execution plan for the given query.
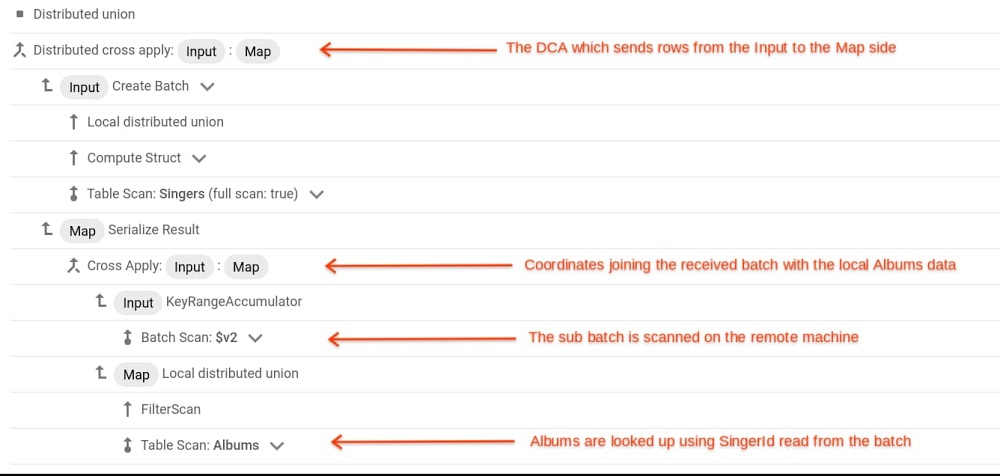
Here is a primer on how to interpret a query execution plan. Each line in the plan is an iterator. The iterators are actually structured in a tree such that the children of an iterator are displayed below it and at the next level of indentation. So in our example, the second from the top line labelled Distributed cross apply has two children; Create Batch and, four lines below that, Serialize Result. You can see that those children each have arrows pointing back to their parent, the Distributed cross apply. Each iterator provides an interface to its parent with the API GetRow. The call allows the parent to ask its child for a row of data. An initial GetRow call made to the root of the tree starts execution. This call percolates down the tree until it reaches leaf nodes. That is where rows are retrieved from storage after which they travel up the tree to the root and ultimately to the application. Dedicated nodes in the tree perform specific functions such as sorting rows or joining two input streams.
In general, to perform a join, it is necessary to move rows from one machine to another. For an index-based join, this moving of rows is performed by the Distributed Cross Apply operator. In the plan you will see that the children of the DCA are labelled Input (the Create Batch) and Map (the Serialize Result). The DCA will move rows from its Input child to its Map child. The actual joining of rows is performed in the Map child and the results are streamed back to the DCA and forwarded up the tree. The first thing to understand is that the Map child of a DCA marks a machine boundary. That is, the Map Child is typically not on the same machine as the DCA. In fact, in general, the Map side is not a single machine. Rather, the tree shape on the Map side (Serialize Result and everything below it in our example) is instantiated for every split of the table on the Map side that might have a matching row. In our example, that’s the Albums table, so if there are ten splits on the Albums table then there will be ten copies of the tree rooted at Serialize Result, each copy responsible for one split and executing on the server that manages that split.
The rows are sent from the Input side to the Map side in batches. The DCA uses the GetRow API to accumulate a batch of rows from its Input side into an in-memory buffer. When that buffer is full, the rows are sent to the Map side. Before being sent, the batch of rows is sorted on the join column. In our example the sort is not necessary because the rows from the Input side are already sorted on SingerId but that will not be the case in general. The batch is then divided into a set of sub-batches, potentially one for each split of the Map side table (Albums). Each row in the batch will be added to the sub-batch of the Map side split that could possibly contain rows that will join with it. The sorting of the batch helps with dividing it into sub batches and also helps the performance of the Map side.
The actual join is performed on the Map side, in parallel, with multiple machines concurrently joining the sub batch they received with the split that they manage. They do that by scanning the sub-batch they received and using the values therein to seek into the indexing structure of the data that they manage. This process is coordinated by the Cross Apply in the plan which initiates the Batch Scan and drives the seeks into the Albums table (see the lines labelled Filter Scan and Table Scan: Albums).
Preserving input order
It may have occurred to you that between sorting the batch and passing the rows between machines, any sort order the rows had in the Input side of the DCA might be lost – and you would be correct. So what happens if you required that order to satisfy an ORDER BY clause – especially important if there is also a LIMIT clause attached to the ORDER BY? There is an order preserving variant of the DCA and Spanner will automatically choose that variant if it will help the query performance. In the order preserving DCA, each row that the DCA receives from its Input child is tagged with a number to record the order in which rows were received. Then, when the rows in a sub batch have generated some join result, they are re-sorted back to the original order.
Left Outer Joins
What if you wanted an outer join? In our example query, perhaps you want to list all singers, even those that don’t have any albums? The query would look like this –
There is a variant of DCA, called a Distributed Outer Apply (DOA) that takes the place of the vanilla DCA. Aside from the name it looks the same as a DCA but provides the semantics of outer join.
Learn more
To get started with Spanner, create an instanceor try it out with a Spanner Qwiklab.