
The Good, the Bad and the Ugly in Cybersecurity – Week 46
November 15, 2019
Palo Alto Networks to Present at Upcoming Investor Conferences
November 18, 2019
Building real-time, interactive data products with open source data and analytics processing technology is not a trivial task. It involves constantly balancing cluster costs with service-level agreements (SLAs). Whether you are using Apache Hadoop and Spark to build a customer-facing web application or a real-time interactive dashboard for your product team, it’s extremely difficult to handle heavy spikes in traffic from a data and analytics perspective.
We’re pleased to announce Cloud Dataproc’s new autoscaling capabilities, now generally available, that can remove the need for complex capacity planning that always results in either missed SLAs or resources sitting idle.
How can autoscaling help your team?
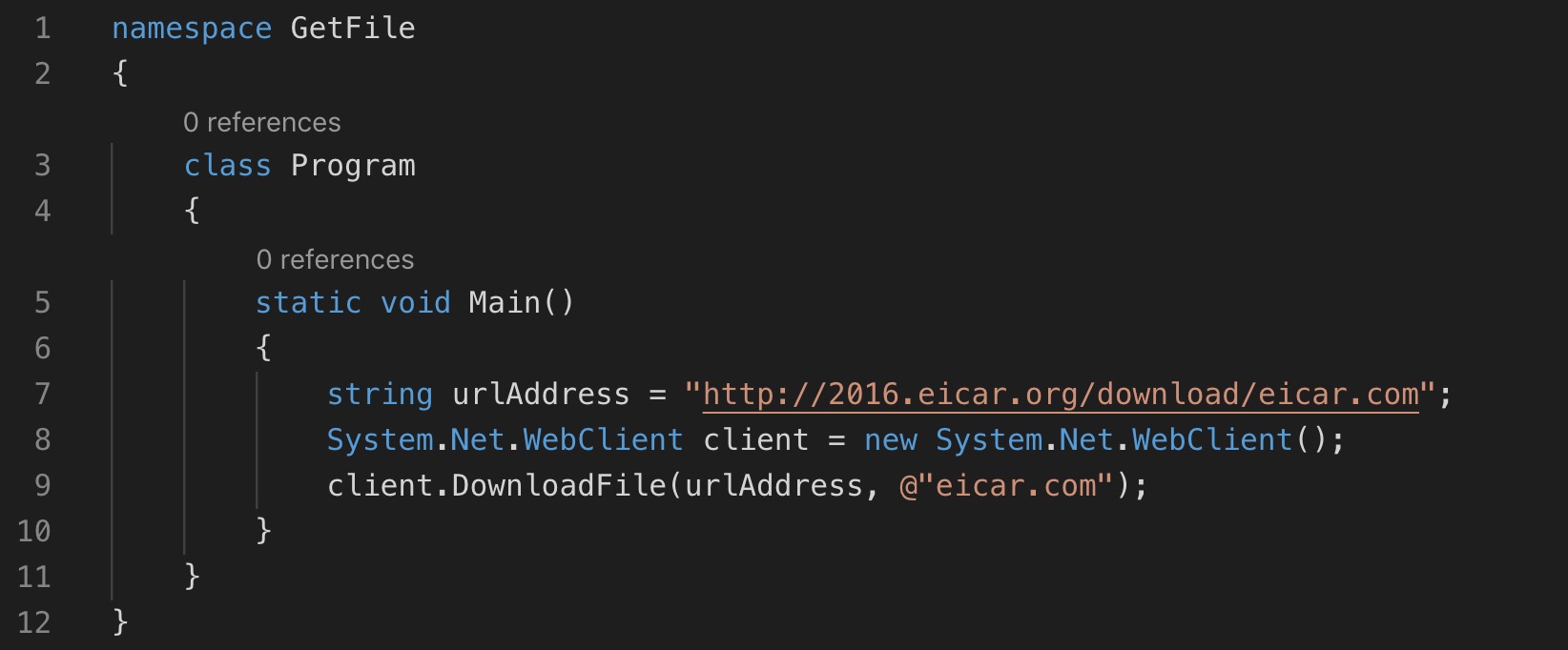
These new capabilities can help a range of teams, whether data engineers building complex ETL pipelines, data analysts running ad hoc SQL queries, or data scientists training a new model. Cloud Dataproc’s autoscaling capabilities allow cluster admins to build ephemeral or long-standing clusters in 90 seconds and apply an autoscaling policy to the cluster to minimize costs and maximize the user experience without manual intervention.
Whether you’re part of the team at a technology company building a SaaS application, a telecommunications company analyzing network traffic, or a retailer monitoring clickstream data during the holidays, you no longer have to worry about right-sizing clusters.
Here’s a look at some common use cases:
