


Getting Started with Microsoft Azure Live Demo
November 6, 2019
Vodafone Idea, Infosys, Indigo and Tata AIG Crowned Winners of the Red Hat APAC Innovation Awards 2019 in India
November 7, 2019
AI & Machine Learning
Google_TPU.jpg
MLPerf is the industry standard for measuring ML performance, and results from the new MLPerf Inference benchmarks are now available. These benchmarks represent performance across a variety of machine learning prediction scenarios. Our submission demonstrates that Google’s Cloud TPU platform addresses the critical needs of machine learning customers: developer velocity, scalability, and elasticity.
MLPerf Inference v0.5 defines three datacenter-class benchmarks: ResNet-50 v1.5 for image classification, SSD-ResNet-34 for object detection, and GNMT for language translation. Google submitted results for all three of these benchmarks using Cloud TPU v3 devices and demonstrated near-linear scalability all the way up to a record 1 million images processed per second on ResNet-50 v1.5 using 32 Cloud TPU v3 devices1.
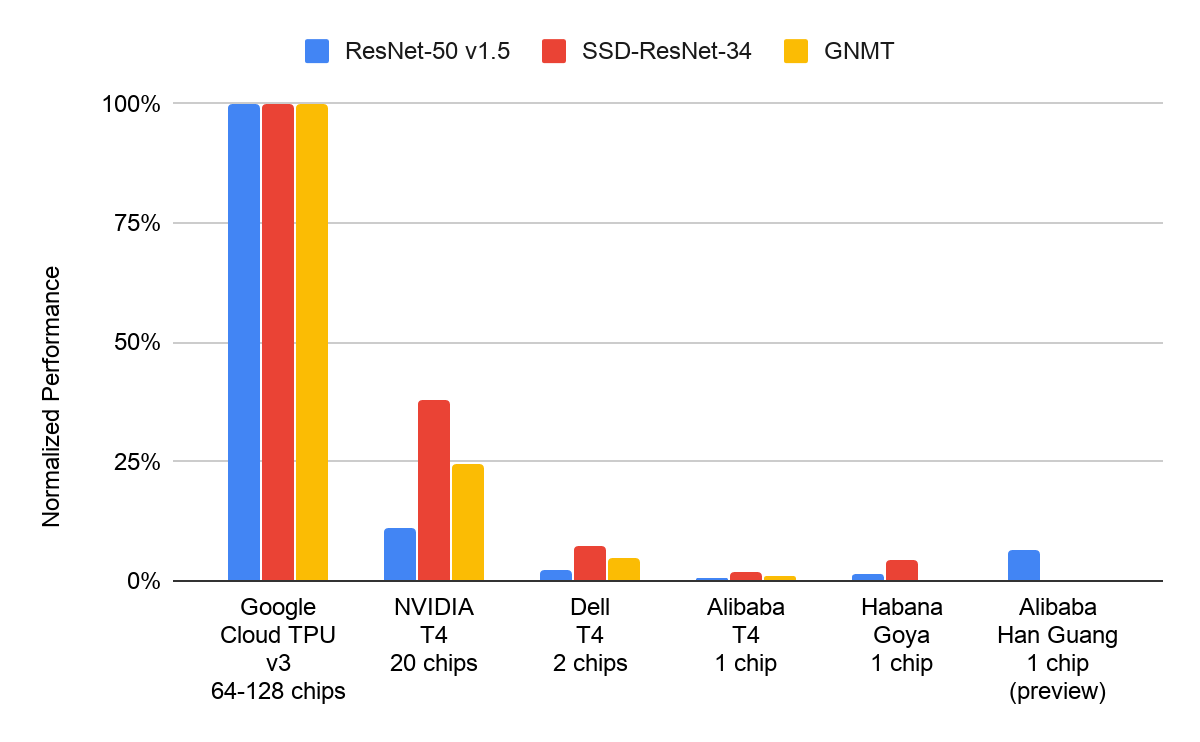
Cloud TPUs are publicly available to Google Cloud customers in beta. These same TPUs are also being used throughout numerous large-scale Google products, including Google Search.
Developer velocity: Serve what you train
The Cloud TPU architecture is designed from the ground up to more seamlessly move ML workloads from training to serving. Cloud TPUs offer bfloat16 floating-point numerics, which allow for greater accuracy compared to integer numerics. Training and serving on the same hardware platform helps prevent potential accuracy losses at inference time and does not require quantization, recalibration, or retraining. In contrast, serving with low precision (e.g., 8-bit) numerics can create major complexities that require significant developer investment to overcome. For example, quantizing a model can add weeks of effort and risk to a project, and it is not always possible for a quantized model to achieve the same accuracy as the original. Inference hardware is lower-cost relative to ML developer effort, so increasing development velocity by serving ML models in higher precision can help save money and improve application quality.
For example, using the TPU v3 platform for both training and inference allows Google Translate to push new models to production within hours of model validation. This enables the team to deploy new advances from machine translation research into production environments faster by eliminating the engineering time required to develop custom inference graphs. This same technology is available to Google Cloud customers to increase the productivity of their machine learning teams, accelerating the development of popular use cases such as call center solutions, document classification, industrial inspection, and visual product search.
Inference at scale
Machine learning inference is highly parallel, with no dependency between one input and the next. MLPerf Inference v0.5 defines two different datacenter inference scenarios: “offline” (e.g. processing a large batch of data overnight) and “online” (e.g. responding to user queries in real-time). Our offline submissions leverage large-scale parallelism to demonstrate high scalability across all three datacenter-class benchmarks. In the case of ResNet-50 v1.5, we show near linear scalability going from 1 to 32 Cloud TPU devices. Google Cloud customers can use these MLPerf results to assess their own needs for inference and choose the Cloud TPU hardware configuration that fits their inference demand appropriately.
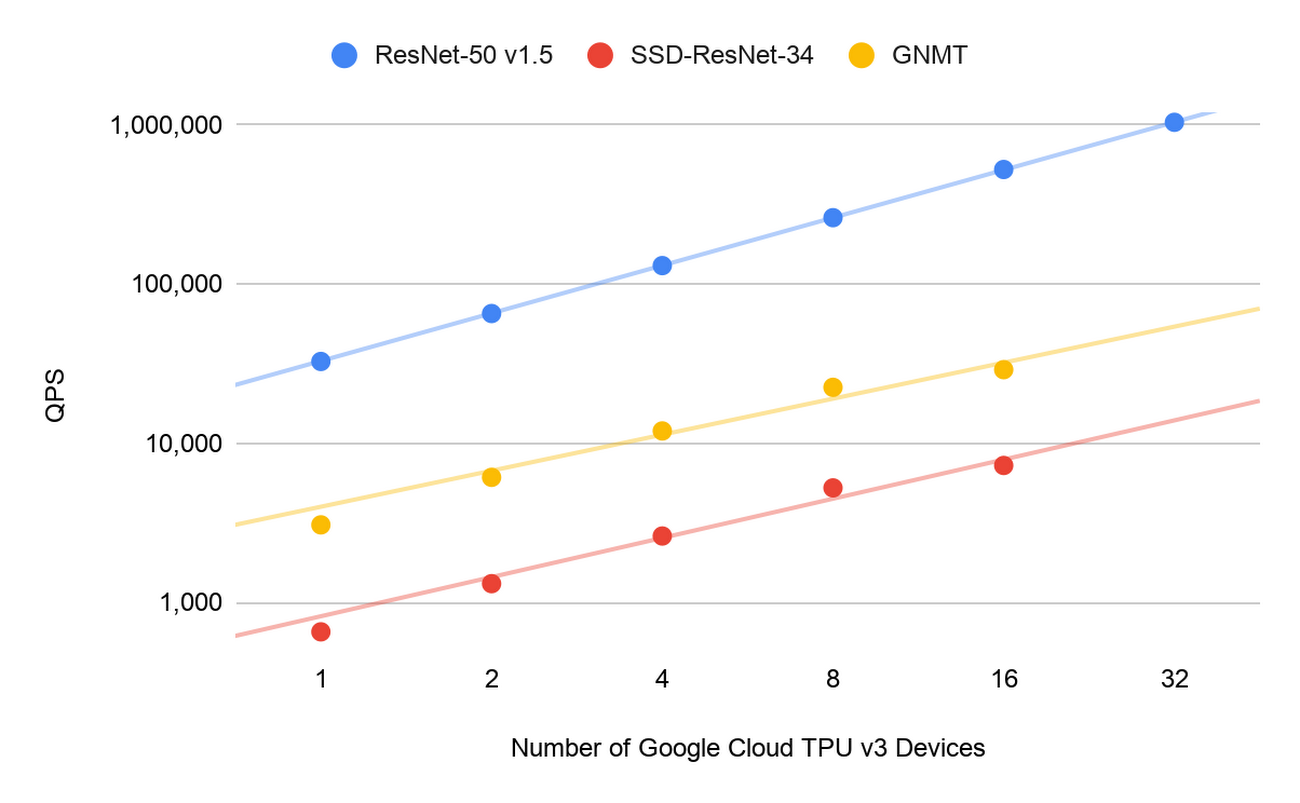
Cloud elasticity: On-demand provisioning
Enterprise inference workloads have time-varying levels of demand for accelerator resources. Google Cloud offers the elasticity needed to adapt to fluctuating demand by provisioning and de-provisioning resources automatically while minimizing cost. Whether customers serve intermittent queries for internal teams, thousands of globally distributed queries every second, or run a giant batch inference job every night, Google Cloud allows them to have just the right amount of hardware to match their demand, minimizing waste due to underutilization of resources.
For example, the Cloud TPU ResNet-50 v1.5 offline submission to MLPerf Inference v0.5 Closed demonstrates that just 32 Cloud TPU v3 devices can collectively process more than one million images per second. To understand that scale and speed, if all 7.7 billion people on Earth uploaded a single photo, you could classify this entire global photo collection in under 2.5 hours and do so for less than $600. With this performance, elasticity and affordability, Google Cloud is uniquely positioned to serve the machine learning needs of enterprise customers.
Get started today
Cloud TPUs have now set records for both training and inference. Google Cloud offers a range of inference solutions for the enterprise, allowing customers to choose among a wide variety of GPUs and Cloud TPUs. For example, we also offer exceptional price/performance with the NVIDIA T4 GPU for inference with quantized models.
Google Cloud customers can get started with accelerated ML inference right away instead of waiting months to build an on-premise ML hardware cluster. If cutting-edge deep learning workloads are a core part of your business, we recommend following the Quickstart guides for Cloud TPUs or GPUs to get familiar with our ML accelerator platforms.
1. MLPerf v0.5 Inference Closed offline; Retrieved from www.mlperf.org 06 November 2019, entry Inf-0.5-20, respectively. MLPerf name and logo are trademarks. See www.mlperf.org for more information.
*2. MLPerf v0.5 Inference Closed offline; Retrieved from www.mlperf.org 06 November 2019, entries Inf-0.5-19, Inf-0.5-20, Inf-0.5-26, Inf-0.5-2, Inf-0.5-1, Inf-0.5-21, Inf-0.5-31, respectively. MLPerf name and logo are trademarks. See www.mlperf.org for more information.
*3. MLPerf v0.5 Inference Closed offline; Retrieved from www.mlperf.org 06 November 2019, entries Inf-0.5-15, Inf-0.5-16, Inf-0.5-17, Inf-0.5-18, Inf-0.5-19, Inf-0.5-20, respectively. MLPerf name and logo are trademarks. See www.mlperf.org for more information.
Related Articles

Get the word out: AutoML Translation goes GA, plus updates to Translation API

ShapeMask: High-performance, large-scale instance segmentation with Cloud TPUs

Bringing Google AutoML to 3.5 million data scientists on Kaggle

Show off your BigQuery ML and Kaggle skills: Competition open now

Reduce the costs of ML workflows with preemptible VMs and GPUs

TensorFlow Enterprise makes accessing data on Google Cloud faster and easier
-
Related Articles
Get the word out: AutoML Translation goes GA, plus updates to Translation API
ShapeMask: High-performance, large-scale instance segmentation with Cloud TPUs
Bringing Google AutoML to 3.5 million data scientists on Kaggle
Show off your BigQuery ML and Kaggle skills: Competition open now
Reduce the costs of ML workflows with preemptible VMs and GPUs
TensorFlow Enterprise makes accessing data on Google Cloud faster and easier
