Data Analytics
GOOGLE_BQ_B_Rnd1.jpg
We hear from our customers that you’re big fans of our BigQuery data warehouse and its features: the ability to handle massive datasets, the petabyte-scale performance, and the ability to create and execute machine learning models in SQL. We also know that you have complex tasks that you execute in your BigQuery environment, like data migration jobs and data quality checkers. Until now, these jobs had to be executed outside BigQuery. We are pleased to announce the beta availability of scripting and stored procedures in all regions where BigQuery is available. These new features can improve your productivity by making complex tasks a lot simpler to perform. They can also offer a way to port migration scripts or run complex ETL logic in BigQuery’s UI or API.
Understanding scripting and stored procedures
Scripting allows data engineers and data analysts to execute a wide range of tasks, from simple ones like running queries in a sequence to complex, multi-step tasks with control flow including IF statements and WHILE loops. Scripting can also help with tasks that make use of variables. If you used BigQuery before this new release, you had to run each step manually and had no control over the execution flow without using other tools.
Stored procedures allow you to save these scripts and run them within BigQuery in the future. Similar to views, you can also share a stored procedure with others in your organization, all while maintaining one canonical version of the procedure.
Here’s an example that demonstrates how you can combine queries and control logic to easily get query results. The result identifies the reporting hierarchy of an employee.
1. Select your project and create a dataset named “dataset” in the BigQuery UI. If you have a different dataset name you want to use, update the dataset name in the script below.
2. Run the following command in the Query Editor:
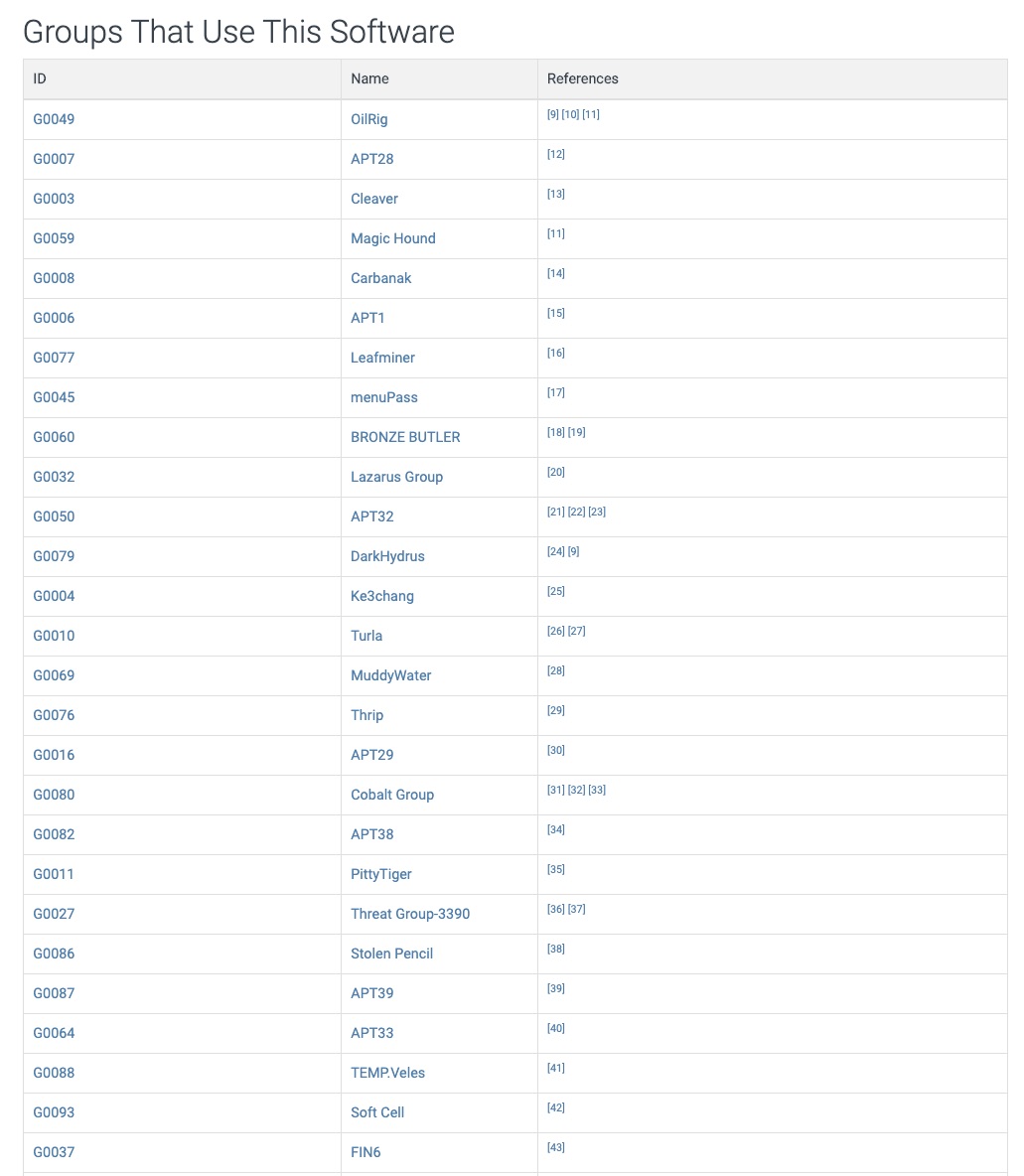
CREATE TABLE dataset.Employees ASSELECT 1 AS employee_id, NULL AS manager_id UNION ALL -- CEOSELECT 2, 1 UNION ALL -- VPSELECT 3, 2 UNION ALL -- ManagerSELECT 4, 2 UNION ALL -- ManagerSELECT 5, 3 UNION ALL -- EngineerSELECT 6, 3 UNION ALL -- EngineerSELECT 7, 3 UNION ALL -- EngineerSELECT 8, 3 UNION ALL -- EngineerSELECT 9, 4 UNION ALL -- EngineerSELECT 10, 4 UNION ALL -- EngineerSELECT 11, 4 UNION ALL -- EngineerSELECT 12, 7 -- Intern;
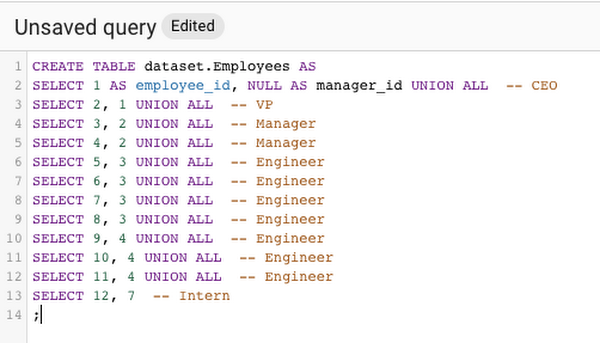
3. Now create a stored procedure that returns the hierarchy for a given employee ID by running the following query:
-- The input variable is employee's employee_id (target_employee_id)-- The output variable (OUT) is employee_hierarchy which lists-- the employee_id of the employee's managerCREATE PROCEDURE dataset.GetEmployeeHierarchy(target_employee_id INT64, OUT employee_hierarchy ARRAY<INT64>)BEGIN-- Iteratively search for this employee's manager, then the manager's-- manager, etc. until reaching the CEO, who has no manager.DECLARE current_employee_id INT64 DEFAULT target_employee_id;SET employee_hierarchy = [];WHILE current_employee_id IS NOT NULL DO-- Add the current ID to the array.SET employee_hierarchy =ARRAY_CONCAT(employee_hierarchy, [current_employee_id]);-- Get the next employee ID by querying the Employees table.SET current_employee_id = (SELECT manager_id FROM dataset.EmployeesWHERE employee_id = current_employee_id);END WHILE;END;
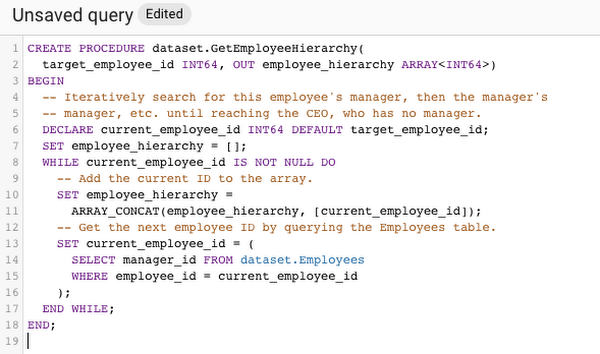
4. Next, after creating the table and the procedure, call the procedure to see the hierarchy for a particular employee ID (Employee ID #9):
-- Change 9 to any other ID to see the hierarchy for that employee.DECLARE target_employee_id INT64 DEFAULT 9;DECLARE employee_hierarchy ARRAY<INT64>;-- Call the stored procedure to get the hierarchy for this employee ID.CALL dataset.GetEmployeeHierarchy(target_employee_id, employee_hierarchy);

-- Show the hierarchy for the employee.SELECT target_employee_id, employee_hierarchy;
Using temporary tables
Temporary tables let BigQuery users save intermediate results to tables as part of scripts and stored procedures. These temporary tables exist at the session level, eliminating the need to save or maintain these tables within datasets.
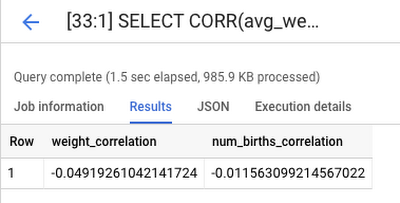
The following example attempts to find a correlation between precipitation and number of births or birth weight in 1988 with the natality public data using temporary tables. (Spoiler alert: It initially looks like there is no correlation!)
-- Day-level natality data is not available after 1988, and-- state-level data is not available after 2004.DECLARE target_year INT64 DEFAULT 1988;CREATE TEMP TABLE SampledNatality ASSELECT DATE(year, month, day) AS date, state, AVG(weight_pounds) AS avg_weight, COUNT(*) AS num_birthsFROM `bigquery-public-data.samples.natality`WHERE year = target_yearAND SAFE.DATE(year, month, day) IS NOT NULL -- Skip invalid datesGROUP BY date, state;IF (SELECT COUNT(*) FROM SampledNatality) = 0 THENSELECT FORMAT("The year %d doesn't have day-level data", target_year);RETURN;END IF;CREATE TEMP TABLE StationsAndStates ASSELECT wban, MAX(state) AS stateFROM `bigquery-public-data.noaa_gsod.stations`GROUP BY wban;CREATE TEMP TABLE PrecipitationByDateAndState ASSELECTDATE(CAST(year AS INT64), CAST(mo AS INT64), CAST(da AS INT64)) AS date,(SELECT state FROM StationsAndStates AS stationsWHERE stations.wban = gsod.wban) AS state,-- 99.99 indicates that precipitation was unknownAVG(NULLIF(prcp, 99.99)) AS avg_prcpFROM `bigquery-public-data.noaa_gsod.gsod*` AS gsodWHERE _TABLE_SUFFIX = CAST(target_year AS STRING)GROUP BY date, state;SELECTCORR(avg_weight, avg_prcp) AS weight_correlation,CORR(num_births, avg_prcp) AS num_births_correlationFROM SampledNatality AS avg_weightsJOIN PrecipitationByDateAndState AS precipitationUSING (date, state);
Here’s what that looks like in the query editor in BigQuery:
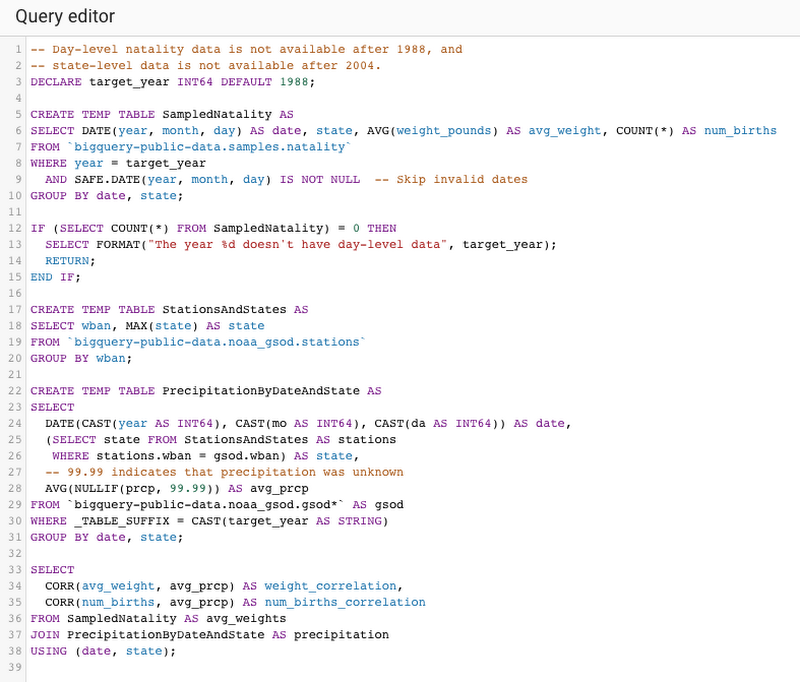
And here are the results of that query:
Getting started
Learn more about scripting in the BigQuery documentation as well as the DDL commands to CREATE and DROP STORED PROCEDUREs and to CREATE TEMPORARY TABLEs. And check out another example and what else is new in BigQuery.
There is no additional cost for the use of scripting and stored procedures; it’s included with the base BigQuery pricing. However, any chargeable operations–such as INSERT, UPDATE, or other operations that result in bytes scanned within scripts or stored procedures–will incur their corresponding costs. Keep this in mind when using those commands with control flow, such as WHILE. And check out the documentation for examples of chargeable operations in scripts.
Happy scripting!
Related Articles

Show off your BigQuery ML and Kaggle skills: Competition open now

Keep Parquet and ORC from the data graveyard with new BigQuery features

TensorFlow Enterprise makes accessing data on Google Cloud faster and easier

Replicate your data from SAP apps to BigQuery with SAP tooling

What’s happening in BigQuery: New features bring flexibility and scale to your data warehouse

Tell compelling stories with your data using Google Sheets
-
Related Articles
Show off your BigQuery ML and Kaggle skills: Competition open now
Keep Parquet and ORC from the data graveyard with new BigQuery features
TensorFlow Enterprise makes accessing data on Google Cloud faster and easier
Replicate your data from SAP apps to BigQuery with SAP tooling
What’s happening in BigQuery: New features bring flexibility and scale to your data warehouse
Tell compelling stories with your data using Google Sheets