Data Analytics
gcp_dataprep_compser.jpg
Performing data analytics in the cloud can lead to great insights and better business outcomes, but you have to start with the right data. Google Cloud’s Cloud Dataprep by Trifacta is our service that explores, cleans, and prepares data to use for analysis, reporting, and machine learning, so you know you have good data before you start using it.
We’re happy to announce the latest release of Cloud Dataprep, which exposes orchestration APIs so you can integrate Cloud Dataprep within your schedulers or other orchestration solutions like Cloud Composer. This means you can expand your automation beyond Cloud Dataflow templates through direct integration in other tools to create repeatable data pipelines for your analytics and AI/ML initiatives–saving time and adding reliability. In addition, this API lets you use dynamic inputs and outputs through Cloud Dataprep variables or parameters–not available using Cloud Dataflow templates. As a result, you can re-use a single Cloud Dataprep flow to execute on a range of input/output values that are evaluated at runtime.
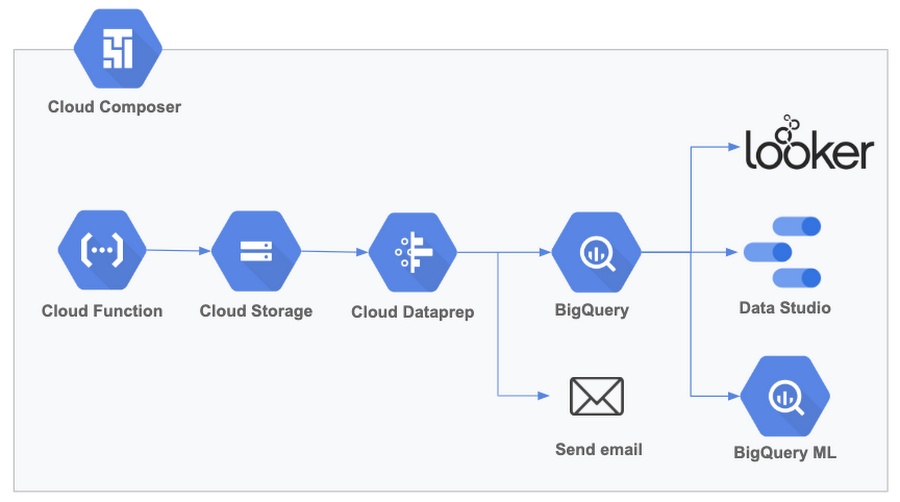
These new features are useful for delivering high-quality data for analytics pipelines that involve multiple tasks executed on a recurring basis. Here’s an example of a common workflow that Cloud Composer can orchestrate including Cloud Dataprep:
We’ve heard from some early adopters implementing this solution for their analytics initiatives.
Woolworths, one of the largest grocery store chains in Australia, was facing multiple challenges to ensure accurate and consistent reporting over time. They rely on numerous internal and external data sources in various formats and standards that they needed to assess and transform to be combined into a single consistent view. This complex orchestration requirement included multiple serverless components and third-party products.
Woolworths has been using Cloud Dataprep to structure and clean the data, then combining it, aggregating it and enriching it with various complex calculations before it could be ready for reporting. But their challenges were not completely solved. They needed to orchestrate the data preparation work within a broader and more comprehensive data pipeline, including ingesting data from other systems, checking consistency, preparing the data, and loading it in BigQuery (sorting data errors and calculation validations), all so the data is ready for reporting in their preferred BI tools and able to be shared via Google Sheets and by email.
Using Cloud Dataprep orchestration APIs along with Cloud Composer lets Woolworths build complex, yet manageable and consistent, end-to-end workflows to deliver accurate data to inform its business.
“With over a thousand stores and hundreds of thousands of employees, Woolworths Australia requires careful planning and optimization of our facilities to maximize returns. Every step to produce useful data insights, from data collection to advanced analytics, influence significantly the company’s strategy,” says Radha Goli, lead data engineer at Woolworths. “With Cloud Dataprep orchestration APIs, we’ll now be able to coordinate our data pipelines within Cloud Composer to guarantee repeatable and trustworthy data outcomes to inform our business.
Getting started with Cloud Dataprep and Cloud Composer
We’ll walk through how you can integrate Cloud Dataprep within a Cloud Composer workflow.
Cloud Composer is a fully managed workflow orchestration service that runs on Google Cloud Platform (GCP) and is built on the popular Apache Airflow open source project. Using Cloud Composer lets you author, schedule, and monitor complex pipelines to help decrease complexity and increase reliability.
This first workflow is very simple, but the principles can be applied to orchestrate much more complex pipelines. Here’s how to create your first pipeline with Cloud Composer and Cloud Dataprep.
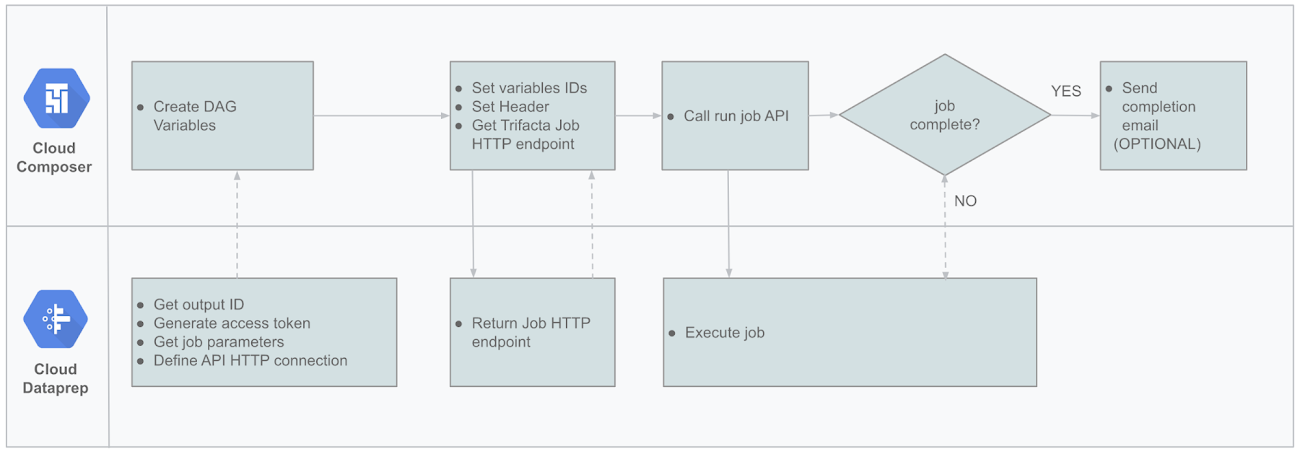
Here’s how to set up the pipeline:
1. Configure variables in Cloud Composer
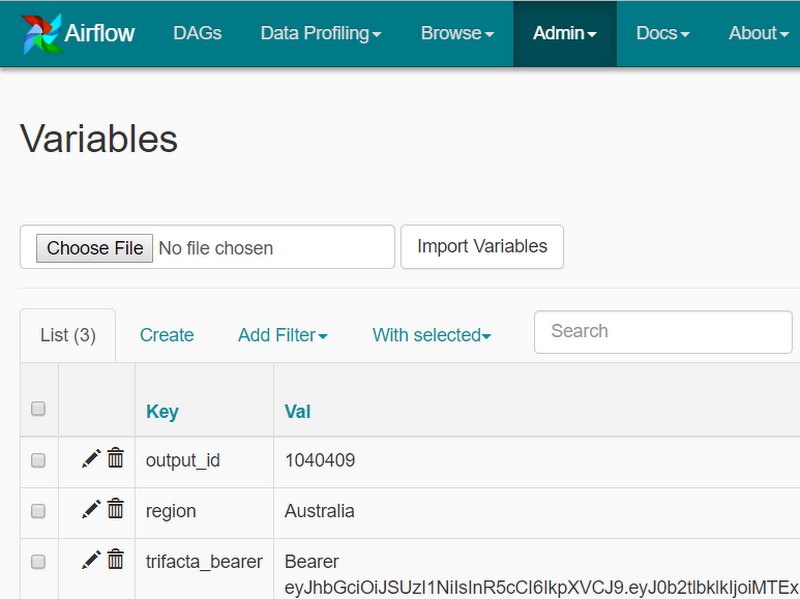
Cloud Composer pipelines are configured as directed acyclic graphs (DAGs) using Python, making it straightforward to get started. Before setting up the DAG, we will need to set up three variables in Cloud Composer. Since we’ll be using the jobGroups API, we’ll have to to store the “output_id” of the output to be executed through the API (see below), as well as the “trifacta_bearer” token used to authenticate (check out the API Access Token documentation). These will be used in our DAG’s code to call the specific output with the correct authentication token.
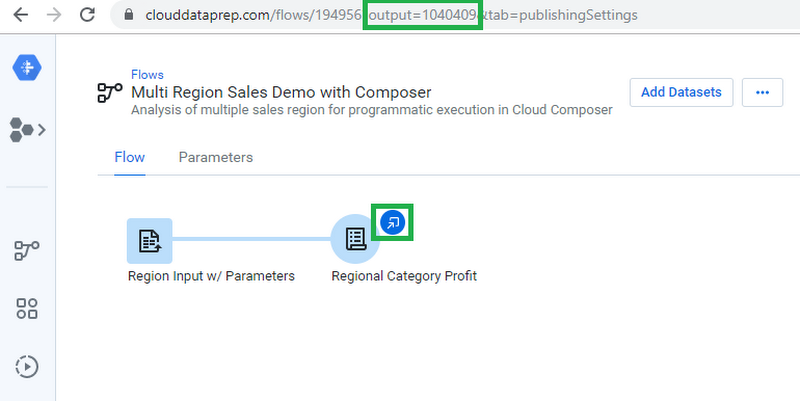
The third variable to set up in Cloud Composer corresponds to the concept in Cloud Dataprep with the exact same name. Variables and parameters in Cloud Dataprep allow you to change the input or output values that are used by the platform at runtime. In this example, we will have an input variable called “region” that can have the values USA, Germany, or Canada, which can be changed for each execution.
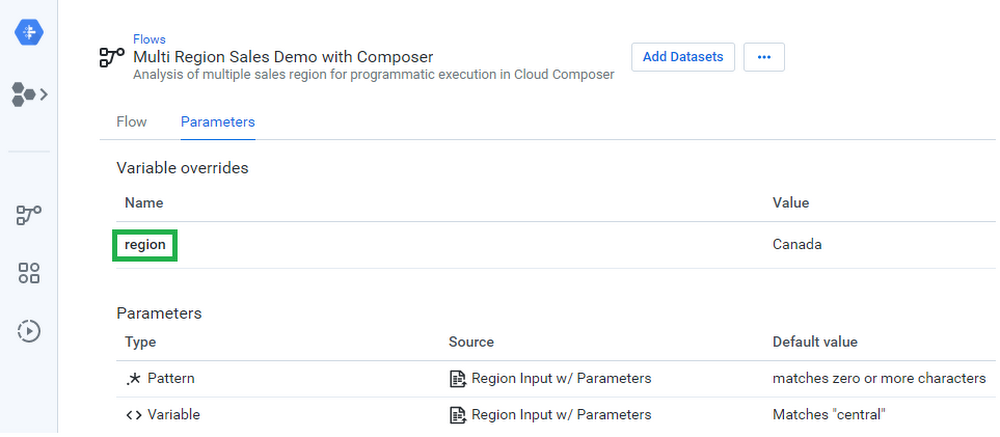
With the variables from Cloud Dataprep, you can launch the Admin/Variables interface in Cloud Composer to create corresponding definitions for these variables in Cloud Composer. We called our variables output_id, region, and trifacta_bearer, and set their respective values.
2. Set up an HTTP connection
Also under the Admin menu, you’ll find the Connections screen. You can either use the default HTTP connection or create a new one. Make sure that your connection is pointing to https://api.clouddataprep.com/<project-id>.
3. Define variable values by their IDs
At the beginning of the DAG, go ahead and define the variables so they can be used later on.
DDAG_NAME = 'dataprep_regional_analysis'output_id = Variable.get("output_id")region = Variable.get("region")
Programmatically call the Dataprep job
In order to kick off the job execution, you will need to create an instance of SimpleHttpOperator(). In this task you define the endpoint, which will hit the recently released jobGroups API. In the body of the request, include the ID of the wrangledDataset, which we called output_id in our DAG variables. Here’s what to do:
1. Define endpoint
def run_flow_and_wait_for_completion():run_flow_task = SimpleHttpOperator(task_id='run_flow',endpoint='/v4/jobGroups',data=json.dumps({"wrangledDataset": {"id": int(recipe_id)},"runParameters": {"overrides": {"data": [{"key": "country","value": country}]}}}),headers=headers,xcom_push=True,dag=dag,)
In the headers definition, make sure to include the regular content-type information as well as dynamically getting the token that was previously stored in the variables:
headers = {"Content-Type": "application/json","Authorization": Variable.get("trifacta_bearer")}
2. Wait for job completion
In the definition of run_flow_and_wait_for_completion(), we also included some logic to check the status of the job. This check task is an instance of Airflow’s HttpSensor class and it uses the poke method at regular intervals to check the status of the job.
wait_for_flow_run_to_complete = HttpSensor(task_id='wait_for_flow_run_to_complete',endpoint='/v4/jobGroups/{{ json.loads(ti.xcom_pull(task_ids="run_flow"))["id"] }}?embed=jobs.errorMessage',headers=headers,response_check=check_flow_run_complete,poke_interval=10,dag=dag,
The check_flow_run_complete returns False if the job is still in progress and True if the job status is equals ‘Complete.’
def check_flow_run_complete(response):return response.json()['status'] == 'Complete'
3. Send email on completion
Using the out-of-the box EmailOperator(), you can easily set up an email notification task:
send_email = EmailOperator(task_id='email_test',to='seanma@trifacta.com',subject='email from airflow',html_content='Your job has completed!',dag=dag)
4. Set task sequence
In Cloud Composer, you can customize the order in which you want your tasks to execute and the dependencies between them. Define the schedule for the DAG, and let it run!
task_sequence = run_flow_and_wait_for_completion()task_sequence.set_downstream(send_email)
Now you’re all set to use these new APIs to integrate Cloud Dataprep within your schedulers or orchestration solutions. This release also comes with new end-user capabilities like Macros, Transform by Example and Cluster Clean. And you can try it out for yourself. Happy data wrangling!
Related Articles

Updates make Cloud AI platform faster and more flexible

Is your pipeline fine? Managing and monitoring a Cloud Dataflow setup

Keeping your Cloud Dataflow pipelines safe with customer-managed encryption keys

Bringing Teradata Vantage to Google Cloud

New geospatial data comes to BigQuery public datasets with CARTO collaboration

Grafana and BigQuery: Together at last
-
Related Articles
Updates make Cloud AI platform faster and more flexible
Is your pipeline fine? Managing and monitoring a Cloud Dataflow setup
Keeping your Cloud Dataflow pipelines safe with customer-managed encryption keys
Bringing Teradata Vantage to Google Cloud
New geospatial data comes to BigQuery public datasets with CARTO collaboration
Grafana and BigQuery: Together at last