

Cloud Immersion Experience: Kubernetes in Action on Azure
June 10, 2019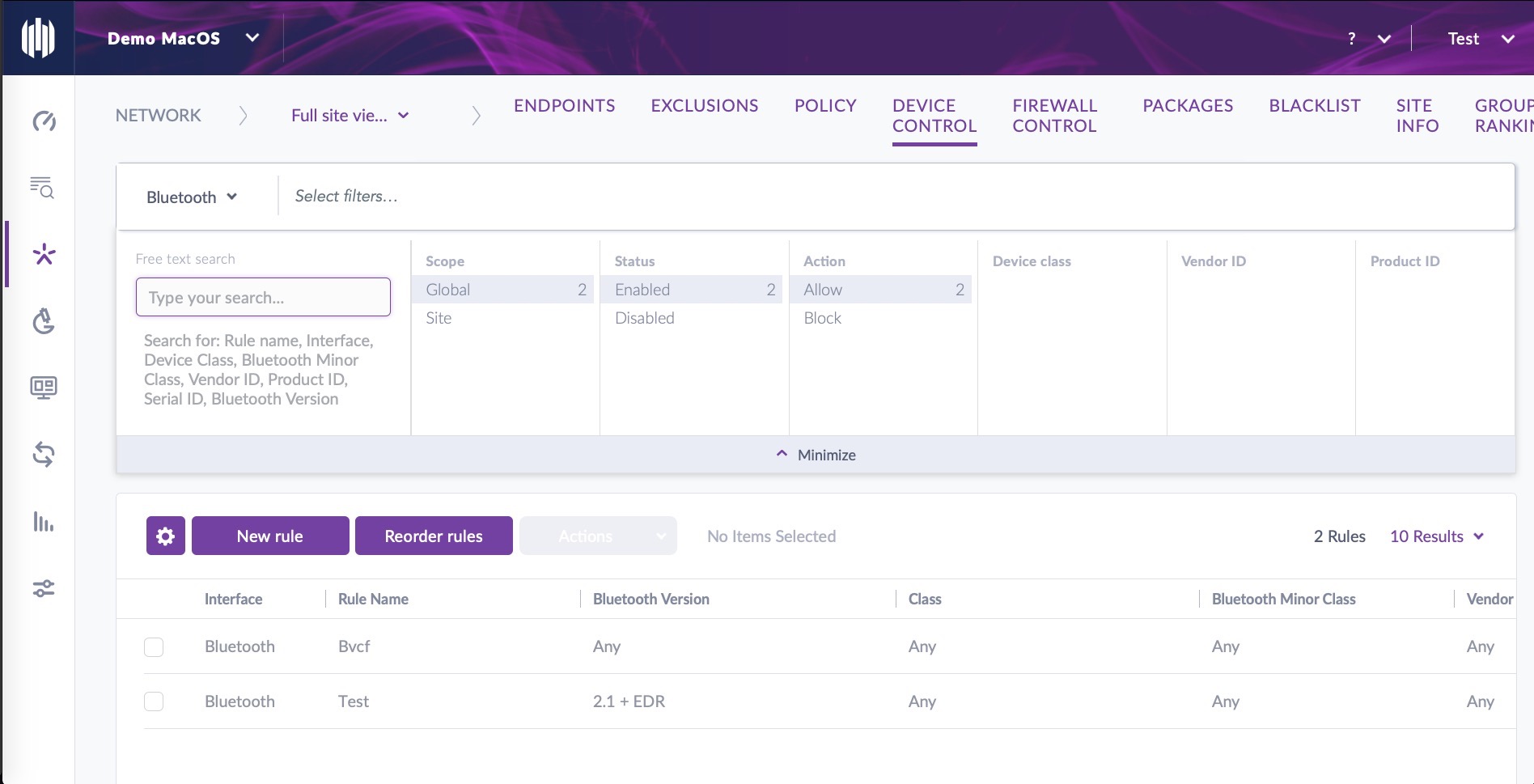
Bluetooth Attacks | Don’t Let Your Endpoints Down
June 10, 2019
Data processing operations can happen a lot faster in the cloud, whether you’re migrating Hadoop-based ETL pipelines from on-premises data centers or building net-new cloud-native approaches for ingesting, processing, and analyzing large volumes of data.
Cloud Dataproc, our managed cloud service for running Apache Spark and Apache Hadoop clusters, is a trusted open-source engine for running big data jobs in production. We know that troubleshooting quickly and accurately is important when you’re using Cloud Dataproc in production, so Google Cloud Platform (GCP) supports the Cloud Dataproc APIs, services, and images, and they’re included in GCP support too.
Cloud Dataproc is one of the data analytics offerings Gartner named a Leader in the 2019 Gartner Magic Quadrant for Data Management Solutions for Analytics. We hear great things from our customers using Cloud Dataproc to run their production processes, whether it’s brand protection with 3PM, enhancing online retail experiences with zulily, or migrating a massive Hadoop environment at Pandora,
We’ve put together the top seven best practices to help you develop highly reliant and stable production processes that use Cloud Dataproc. These will help you process data faster to get better insights and outcomes.
1. Specify cluster image versions.
Cloud Dataproc uses image versions to bundle operating system and big data components (including core and optional components) and GCP connectors into a single package that is deployed on a cluster.
If you don’t specify an image version when creating a new cluster, Cloud Dataproc will default to the most recent stable image version. For production environments, we recommend that you always associate your cluster creation step with a specific minor Cloud Dataproc version, as shown in this example gcloud command:
gcloud dataproc clusters create my-pinned-cluster --image-version 1.4-debian9
This will ensure you know the exact OSS software versions that your production jobs use. While Cloud Dataproc also lets you specify a subminor version (i.e., 1.4.xx rather than 1.4) in most environments, it’s preferable to reference Cloud Dataproc minor versions only (as shown in the gcloud command). Sub-minor versions will be updated periodically for patches or fixes, so that lets new clusters automatically get security updates without breaking compatibility.
New minor versions of Cloud Dataproc are made available in a preview, non-default mode before they become the default. This lets you test and validate your production jobs against new versions of Cloud Dataproc before making the version substitution. Learn more about Cloud Dataproc versioning.
2. Know when to use custom images.
If you have dependencies that must be shipped with the cluster, like native Python libraries that must be installed on all nodes, or specific security hardening software or virus protection software requirements for the image, you should create a custom image from the latest image in your target minor track. This allows those dependencies to be met each time. You should update the subminor within your track each time you rebuild the image.
3. Use the Jobs API for submissions.
The Cloud Dataproc Jobs API makes it possible to submit a job to an existing Cloud Dataproc cluster with a jobs.submit call over HTTP, using the gcloud command-line tool or the GCP Console itself. It also makes it easy to separate the permissions of who has access to submit jobs on a cluster and who has permissions to reach the cluster itself, without setting up gateway nodes or having to use something like Apache Livy.
The Jobs API makes it easy to develop custom tooling to run production jobs. In production, you should strive for jobs that only depend on cluster-level dependencies at a fixed minor version (i.e., 1.3). Bundle dependencies with jobs as they are submitted. An uber jar submitted to Spark or MapReduce is one common way to do ths.
4. Control the location of your initialization actions.
Initialization actions let you provide your own customizations to Cloud Dataproc. We’ve taken some of the most commonly installed OSS components and made example installation scripts available in the dataproc-initializaton-actions GitHub repository.
While these scripts provide an easy way to get started, when you’re running in a production environment you should always run these initialization actions from a location that you control. Typically, a first step is to copy the Google-provided script into your own Cloud Storage location.
As of now, the actions are not snapshotted and updates are often made to the public repositories. If your production code simply references the Google version of the initialization actions, unexpected changes may leak into your production clusters.
5. Keep an eye on Dataproc release notes.
Cloud Dataproc releases new sub-minor image versions each week. To stay on top of all the latest changes, review the release notes that accompany each change to Cloud Dataproc. You can also add this URL into your favorite feed reader.
6. Know how to investigate failures.
Even with these practices in place, an error may still occur. When an error occurs because of something that happens within the cluster itself and not simply in a Cloud Dataproc API call, the first place to look will be your cluster’s staging bucket. Typically, you will be able to find the Cloud Storage location of your cluster’s staging bucket in the error message itself. It may look something like this:
ERROR:
(gcloud.dataproc.clusters.create) Operation [projects/YOUR_PROJECT_NAME/regions/YOUR_REGION/operations/ID] failed:
Multiple Errors:
– Initialization action failed. Failed action ‘gs://your_failed_action.sh’, see output in:
gs://dataproc-BUCKETID-us-central1/google-cloud-dataproc-metainfo/CLUSTERID/cluster-d135-m/dataproc-initialization-script-0_output
With this error message, you can often diagnose the error with a simple cat on the file to identify the cause of the error. For example, this:
gsutil cat gs://dataproc-BUCKETID-us-central1/google-cloud-dataproc-metainfo/CLUSTERID/cluster-d135-m/dataproc-initialization-script-0_output
Returns this:
+ readonly RANGER_VERSION=1.2.0
+ err ‘Ranger admin password not set. Please use metadata flag – default-password’
++ date +%Y-%m-%dT%H:%M:%S%z
+ echo ‘[2019-05-13T22:05:27+0000]: Ranger admin password not set. Please use metadata flag – default-password’
[2019-05-13T22:05:27+0000]: Ranger admin password not set. Please use metadata flag – default-password
+ return 1
…which shows that we had forgotten to set a metadata password property for our Apache Ranger initialization action.
7. Research your support options.
Google Cloud is here to support your production OSS workloads and help meet your business SLAs, with various tiers of support available. In addition, Google Cloud Consulting Services can help educate your team on best practices and provide guiding principles for your specific production deployments.
To hear more tips about running Cloud Dataproc in a production environment, check out this presentation from Next ’19 with Cloud Dataproc user Dunnhumby.
