When you’re developing a set of apps or services that are coordinated by, or dependent on, an event, you can take an event-sourced approach to model that system in a thorough way. Event-sourced systems are great for solving a variety of very complex development problems, triggering a series of tasks based on an event, and creating an ordered list of events to process into audit logs. But there isn’t really an off-the-shelf solution for getting an event-sourced system up and running.
With that in mind, we are pleased to announce a newly published guide to Deploying Event-Sourced Systems with Cloud Spanner, our strongly consistent, scalable database service that’s well-suited for this project. This guide walks you through the why and the how of bringing this event-sourced system into being, and how to tackle some key challenges, like keeping messages in order, creating a schema registry, and triggering workloads based on published events. Based on the feedback we got while talking through this guide with teammates and customers, we went one step further: We are pleased to announce working versions of the apps described in the guide, available in our Github repo, so you can easily introduce event-sourced development into your own environment.
Getting started deploying event-sourced systems
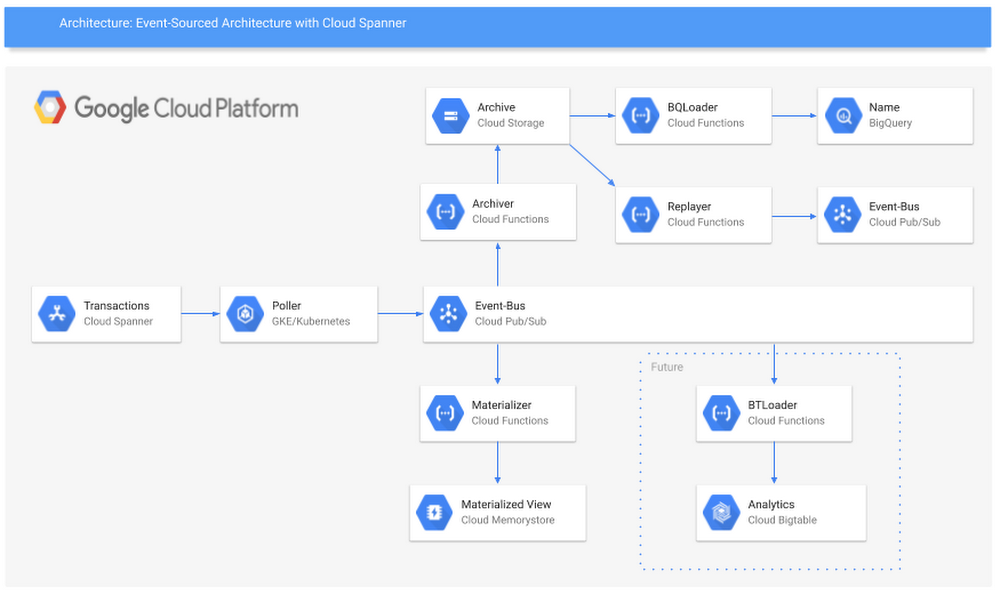
In the guide, you’ll find out how to make an event-sourced system that uses Cloud Spanner as the ingest sink, then automatically publishes each record to Cloud Pub/Sub. Cloud Spanner as a sink solves two key challenges of creating event-sourced systems: performing multi-region writes and adding global timestamps.
Multi-region writes are necessary for systems that run in multiple places–think on-prem and cloud, east and west coast for disaster recovery, etc. Multi-region writes are also great for particular industries, like retailers that want to send events to a single system from each of their stores for things like inventory tracking, rewards updates, and real-time sales metrics.
Cloud Spanner also has the benefit of TrueTime, letting you easily add a globally consistent timestamp for each of your events. This establishes a ground truth of the order of all your messages for all time. This means you can make downstream assumptions anchored in that ground truth, which solves all sorts of complexity for dependent systems and services.
In the guide, we use Avro as a serialization format. The two key reasons for this are that the schema travels with the message, and BigQuery supports direct uploading of Avro records. So even if your events change over time, you can continue to process them using the same systems without having to maintain and update a secondary schema registry and versioning system. Plus, you get an efficient record format on the wire and for durable storage.
Finally, we discuss storing each record in Cloud Storage for archiving and replay. With this strategy, you can create highly reliable long-term storage and your system of record in Cloud Storage, while also allowing your system to replay records from any timestamp in the past. This concept can build the foundation for a backup and restore pattern for Cloud Spanner, month-over-month analysis of events, and even end-of-month reports or audit trails.
Here’s a look at the architecture described in the guide, and details about the services and how you can deploy them.