Cloud Pub/Sub, part of Google Cloud Platform (GCP), lets you ingest event streams from a wide variety of data sources, at nearly any scale, and allows horizontal application scaling without additional configuration. This model allows customers to sidestep complexities in operations, scaling, compliance, security, and more, leading to simpler pipelines for analytics and machine learning. However, Cloud Pub/Sub’s enablement of horizontal scaling adds the additional requirement to orchestrate multiple machines (instances or Cloud Pub/Sub clients). So to verify that Cloud Pub/Sub client libraries can handle high-throughput single-machine workloads, we must first understand the performance characteristics of a single, larger machine.
With that in mind, we’ve developed an open-source load test framework, now available on GitHub. In this post, you’ll see single-machine application benchmarks showing how Cloud Pub/Sub can be expected to scale for various programming languages and scenarios. These details should also help you understand how a single Cloud Pub/Sub client is expected to scale using different client libraries, as well as how to tune the settings of these libraries to achieve maximum throughput. Note that the Cloud Pub/Sub service is designed to scale seamlessly with the traffic you send to it from one or more clients; the aggregate throughput of the Cloud Pub/Sub system is not being measured here.
Here’s how we designed and tested this framework.
Setting up the test parameters
We will publish and subscribe from single, distinct Compute Engine instances of various sizes running Ubuntu 16.04 LTS. The test creates a topic and publishes to it from a single machine as fast as it can. The test also creates a single subscription to that topic, and a different machine reads as many messages as possible from that subscription. We’ll run the primary tests with 1KB-sized messages, typical of real-world Cloud Pub/Sub usage. Tests will be run for a 10-minute burn-in period, followed by a 10-minute measurement period. The code we used for testing is publicly available on GitHub, and you can find results in their raw form here.
Using vertical scaling
As the number of cores in the machine increases, the corresponding publisher throughput should be able to increase to process the higher number of events being generated. To do so, you’ll want to choose a strategy depending on the language’s ability for thread parallelism. For thread-parallelizable languages such as Java, Go, and C#, you can increase publisher throughput by having more threads generating load for a single publisher client. In the test, we set the number of threads to five times the number of physical cores. Because we are publishing in a tight loop, we used a rate limiter to prevent running out of memory or network resources (though this would probably not be needed for a normal workflow). We tuned the number of threads per core on the subscribe side on a per-language basis, and ran both Java and Go tests at the approximate optimum of eight threads/goroutines per core.
For Python, Node, Ruby and PHP, which use a process parallelism approach, it’s best to use one publisher client per hardware core to enable maximum throughput. This is because GRPC, upon which the client libraries tested here are built, requires tricky initialization after all processes have been forked to operate properly.
Getting the test results
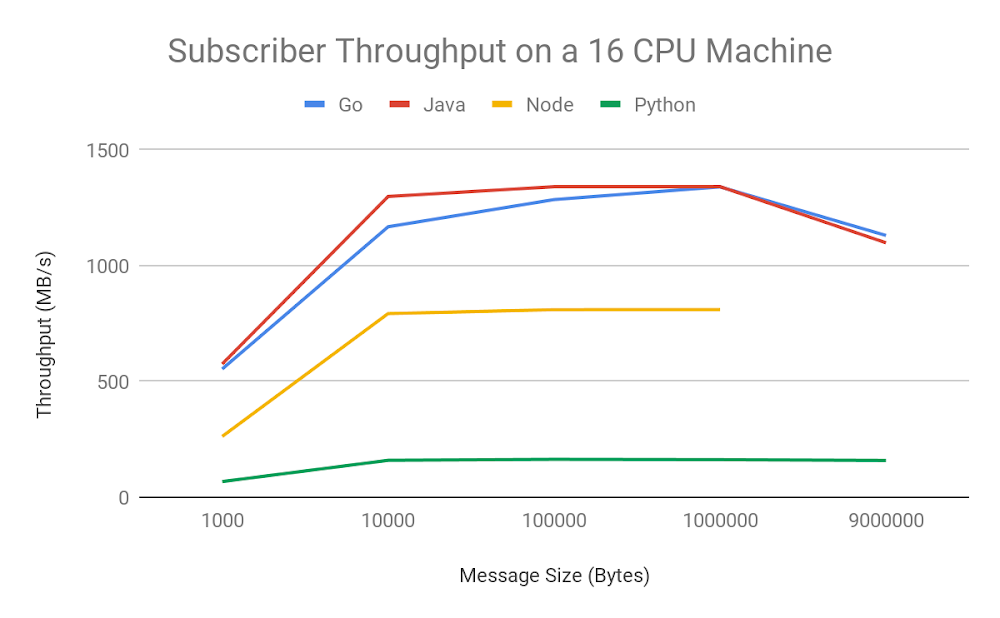
The following are results from running the load test framework under various conditions in Go, Java, Node and Python, the four most popular languages used for Cloud Pub/Sub. These results should be representative of the best-case performance of similar languages when only minimal processing is done per message. C# performance should be similar to Java and Go, whereas Ruby and PHP would likely exhibit performance on par with Python.
To achieve maximum publisher throughput, we set the batching settings to create the largest batches allowed by the service, the maximum of either 1,000 messages or 10MB per batch, whichever is smaller. Note that these may not be the optimal settings for all use cases. Larger batch settings and longer wait times can delay message persistence and increase per-message latency.
In testing, we found that publisher throughput effectively scales with an increase in available machine cores. Compiled/JIT language throughput from Java, Go and Node is significantly better than that of Python. For high-throughput publish use cases such as basic data transfer, you should choose one of these languages. Note that Java performs the best among the three. You can see here how each performed:


