Databases
cloudai_solutions.jpg
Redis is one of the most popular open source in-memory data stores, used as a database, cache and message broker. This post covers the major deployment scenarios for Redis on Google Cloud Platform (GCP). In the following post, we’ll go through the pros and cons of these deployment scenarios and the step-by-step approach, limitations and caveats for each.
Deployment options for running Redis on GCP
There are four typical deployment scenarios we see for running Redis on GCP: Cloud Memorystore for Redis, Redis Labs Cloud and VPC, Redis on Google Kubernetes Engine (GKE), and Redis on Google Compute Engine. We’ll go through the considerations for each of them. It’s also important to have backup for production databases, so we’ll discuss backup and restore considerations for each deployment type.
Cloud Memorystore for Redis
Cloud Memorystore for Redis, part of GCP, is a way to use Redis and get all its benefits without the cost of managing Redis. If you need data sharding, you can deploy open source Redis proxies such as Twemproxy and Codis with multiple Cloud Memorystore for Redis instances for scale until Redis Cluster becomes ready in GCP.
Twemproxy
Twemproxy, also known as the nutcracker, is an open source (under the Apache License) fast and lightweight Redis proxy developed by Twitter. The purpose of Twemproxy is to provide a proxy and data sharding solution for Redis and to reduce the number of client connections to the back-end Redis instances. You can set up multiple Redis instances behind Twemproxy. Clients only talk to the proxy and don’t need to know the details of back-end Redis instances, which simplifies management. You can also run multiple Twemproxy instances for the same group of back-end Redis servers to prevent having a single point of failure, as shown here:
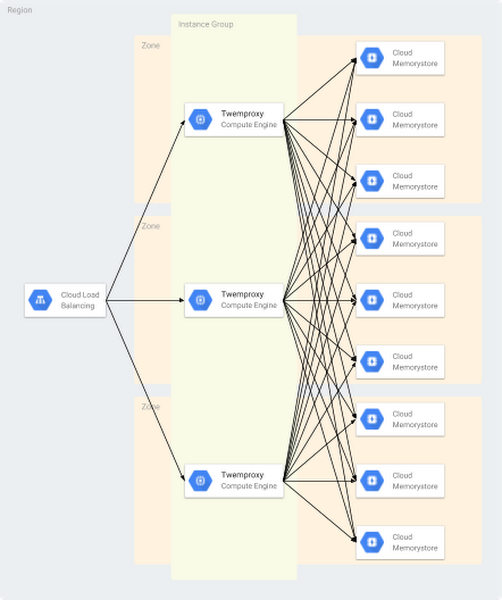
Note that Twemproxy does not support all Redis commands, such as pub/sub and transaction commands. In addition, it’s not convenient to add or remove back-end Redis nodes for Twemproxy. It requires you to restart Twemproxy for configurations to be effective, and data isn’t rebalanced automatically after adding or removing Redis nodes.
Codis
Codis is an open source (under the MIT License) proxy-based high-performance Redis cluster tool developed by CodisLabs. Codis offers another Redis data sharding proxy option to solve the horizontal scalability limitation and lack of administration dashboard. It’s fully compatible with Twemproxy and has a handy tool called redis-port that handles the migration from Redis Twemproxy to Codis.
Pros of Cloud Memorystore for Redis
- It’s fully managed. Google fully manages administrative tasks for Redis instances such as hardware provisioning, setup and configuration management, software patching, failover, monitoring and other nuances that require considerable effort for service owners who just want to use Redis as a memory store or a cache.
- It’s highly available. We provide a standard Cloud Memorystore tier, in which we fully manage replication and failover to provide high availability. In addition, you can keep the replica in a different zone.
- It’s scalable and performs well. You can easily scale memory that’s provisioned for Redis instances. We also provide high network throughput per instance, which can be scaled on demand.
- It’s updated and secure. We provide network isolation so that access to Redis is restricted to within a network via a private IP. Also, OSS compatibility is Redis 3.2.11, as of late 2018.
Cons of Cloud Memorystore for Redis
- Some features are not yet available: Redis Cluster, backup and restore.
- It lacks replica options. Cloud Memorystore for Redis provides a master/replica configuration in the standard tier, and master and replica are spread across zones. There is only one replica per instance.
- There are some product constraints you should note.
You can deploy OSS proxies such as Twemproxy and Codis with multiple Cloud Memorystore for Redis instances for scalability until Redis Cluster is ready in GCP. And note the caveat that basic-tier Cloud Memorystore for Redis instances are subject to a cold restart and full data flush during routine maintenance, scaling, or an instance failure. Choose the standard tier to prevent data loss during those events.
How to get started
Check out our Cloud Memorystore for Redis guide for the basics. You can see here how to configure multiple Cloud Memorystore for Redis instances using Twemproxy and an internal load balancer in front of them.
1. Create nine new Cloud Memorystore for Redis instances in asia-northeast1 region
$ for i in {1..9}; do gcloud redis instances create redis${i} --size=1 --region=asia-northeast1 --tier=STANDARD; done
2. Prepare a Twemproxy container for deployment
$ mkdir twemproxy$ cd twemproxy$ cat <<EOF > nutcracker.ymlalpha:listen: 0.0.0.0:26379hash: fnv1a_64distribution: ketamatimeout: 1000backlog: 512preconnect: trueredis: trueauto_eject_hosts: trueserver_retry_timeout: 2000server_failure_limit: 2servers:EOF$ gcloud redis instances list --region=asia-northeast1 | awk '{ printf " - %s:%s:1n", $5, $6 }' | tail -n +2 >> nutcracker.yml$ cat <<EOF > DockerfileFROM gliderlabs/alpine:3.3RUN echo "http://dl-cdn.alpinelinux.org/alpine/edge/testing" >> /etc/apk/repositoriesRUN apk add --update twemproxyEXPOSE 26379COPY nutcracker.yml /etc/nutcracker/ENTRYPOINT ["/usr/sbin/nutcracker"]CMD ["-c", "/etc/nutcracker/nutcracker.yml"]EOF
3. Build a Twemproxy docker image
$ gcloud builds submit --tag gcr.io/<your-project>/twemproxy .
* Please replace <your-project> with your GCP project ID.
Note that a VM instance starts a container with –network=”host” flag of the Docker run command by default.
4. Create an instance template based on the Docker image
$ gcloud compute instance-templates create-with-container twemproxy --machine-type=n1-standard-8 --tags=twemproxy-26379,allow-health-checks-tcp --container-image gcr.io/<your-project>/twemproxy:latest
* Please replace <your-project> with your GCP project ID.
5. Create a managed instance group using the template
$ gcloud compute instance-groups managed create ig-twemproxy --base-instance-name ig-twemproxy --size 3 --template twemproxy --region asia-northeast1$ gcloud compute instance-groups managed set-autoscaling ig-twemproxy --max-num-replicas 10 --min-num-replicas 3 --target-cpu-utilization 0.6 --cool-down-period 60 --region asia-northeast1
6. Create a health check for the internal load balancer
$ gcloud compute health-checks create tcp hc-twemproxy --port 26379 --check-interval 5 --healthy-threshold 2
7.Create a back-end service for the internal load balancer
$ gcloud compute backend-services create ilb-twemproxy --load-balancing-scheme internal --session-affinity client_ip_port_proto --region asia-northeast1 --health-checks hc-twemproxy --protocol tcp
8. Add instance groups to the back-end service
$ gcloud compute backend-services add-backend ilb-twemproxy --instance-group ig-twemproxy --instance-group-region asia-northeast1 --region asia-northeast1
9. Create a forwarding rule for the internal load balancer
$ gcloud compute forwarding-rules create fr-ilb-twemproxy --load-balancing-scheme internal --ip-protocol tcp --ports 26379 --backend-service ilb-twemproxy --region asia-northeast1
10. Configure firewall rules to allow the internal load balancer access to Twemproxy instances
$ gcloud compute firewall-rules create allow-twemproxy --action allow --direction INGRESS --source-ranges 10.128.0.0/20 --target-tags twemproxy-26379 --rules tcp:26379$ gcloud compute firewall-rules create allow-health-checks-tcp --action allow --direction INGRESS --source-ranges 130.211.0.0/22,35.191.0.0/16 --target-tags allow-health-checks-tcp --rules tcp
Redis Labs Cloud and VPC
To get managed Redis Clusters, you can use a partner solution from Redis Labs. Redis Labs has two managed-service options: Redis Enterprise Cloud (hosted) and Redis Enterprise VPC (managed).
- Redis Enterprise Cloud is a fully managed and hosted Redis Cluster on GCP.
- Redis Enterprise VPC is a fully managed Redis Cluster in your virtual private cloud (VPC) on GCP.
Redis Labs Cloud and VPC protect your database by maintaining automated daily and on-demand backups to remote storage. You can back up your Redis Enterprise Cloud/VPC databases to Cloud Storage. Find instructions here.
You can also import a data set from an RDB file using Redis Labs Cloud with VPC. Check out the official public document on Redis Labs site for instructions.
Pros of Redis Labs Cloud and VPC
- It’s fully managed. Redis Labs manages all administrative tasks.
- It’s highly available. These Redis Labs products include an SLA with 99.99% availability.
- It scales and performs well. It will automatically add new instances to your cluster according to your actual data set size without any interruption to your applications.
- It’s fully supported. Redis Labs supports Redis itself.
Cons of Redis Labs Cloud and VPC
-
There’s a cost consideration. You’ll have to pay separately for Redis Labs’ service.
How to get started
Contact Redis Labs to discuss further steps.
Redis on GKE
If you want to use Redis Cluster, or want to read from replicas, Redis on GKE is an option. Here’s what you should know.
Pros of Redis on GKE
- You have full control of the Redis instances. You can configure, manage and operate as you like.
- You can use Redis Cluster.
- You can read from replicas.
Cons of Redis on GKE
- It’s not managed. You’ll need to manage administrative tasks such as hardware provisioning, setup and configuration management, software patching, failover, backup and restore, configuration management, monitoring, etc.
- Availability, scalability and performance varies, depending on how you architect. Running a standalone instance of Redis on GKE is not ideal for production because it would be a single point of failure, so consider configuring master/slave replication to have redundant nodes with Sentinel, or set up a cluster.
- There’s a steeper learning curve. This option requires you to learn Redis itself in more detail. Kubernetes also requires some time to learn, and its deployment may introduce additional complexity to your design and operations.
- When using Redis on GKE, you’ll want to be aware of GKE cluster node maintenance; cluster nodes will need to be upgraded once every three months or so. To avoid unexpected disruption during the upgrade process, consider using PodDisruptionBudgets and configure parameters appropriately. And you’ll want to run containers in host networking mode to eliminate additional network overhead from Docker networking. Make sure that you run one Redis instance on each VM, otherwise it may cause port conflicts. This can be achieved with podAntiAffinity.
How to get started
Use Kubernetes to deploy a container to run Redis on GKE. The example below shows the steps to deploy Redis Cluster on GKE.
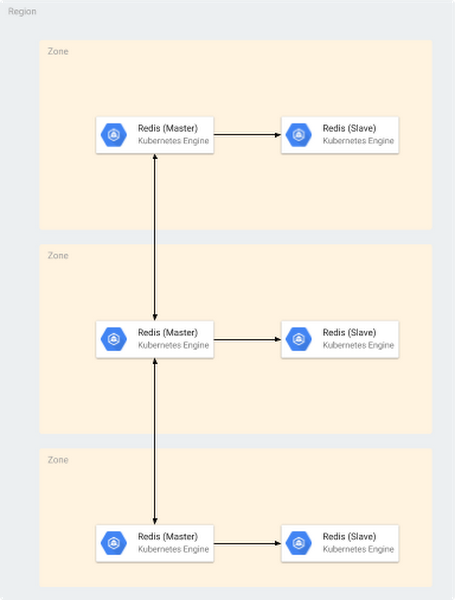
1. Provision a GKE cluster
$ gcloud container clusters create redis-cluster --num-nodes 6 --machine-type n1-standard-8 --image-type COS --disk-type pd-standard --disk-size 100 --enable-ip-alias --create-subnetwork name=redis-subnet
* If prompted, specify your preferred GCP project ID or zone.
2. Clone an example git repository
$ git clone https://github.com/GoogleCloudPlatform/professional-services.git$ cd professional-services/examples/redis-cluster-gke
3. Create config maps
$ kubectl create -f configmaps/
4. Deploy Redis pods
$ kubectl create -f redis-cache.yaml
* Wait until it is completed.
5. Prepare a list of Redis cache nodes
$ kubectl get pods -l app=redis,redis-type=cache -o wide | tail -n +2 | awk '{printf "%s:%s ",$6,"6379"}' > redis-nodes.txt$ kubectl create configmap redis-nodes --from-file=redis-nodes.txt
6. Submit a job to configure Redis Cluster
$ kubectl create -f redis-create-cluster.yaml
7. Confirm the job “redis-create-cluster-xxxxx” shows completed status
$ kubectl get poNAME READY STATUS RESTARTS AGEredis-cache-55dfdcb84c-4tzh4 1/1 Running 0 5mredis-cache-55dfdcb84c-79kkn 1/1 Running 0 5mredis-cache-55dfdcb84c-98gn9 1/1 Running 0 5mredis-cache-55dfdcb84c-t4gc6 1/1 Running 0 5mredis-cache-55dfdcb84c-ttg85 1/1 Running 0 5mredis-cache-55dfdcb84c-xdbz8 1/1 Running 0 5mredis-create-cluster-cpjsp 0/1 Completed 0 3m
Limitations highly depend on how you design the cluster.
Backing up and restoring manually built Redis
Both GKE and Compute Engine will follow the same method to back up and restore your databases. Basically, copying the RDB file is completely safe while the server is running, because the RDB is never modified once produced.
To back up your data, copy the RDB file to somewhere safe, such as Cloud Storage.
- Create a cron job in your server to take hourly snapshots of the RDB files in one directory, and daily snapshots in a different directory.
- Every time the cron script runs, make sure to call the “find” command to make sure old snapshots are deleted: for instance, you can take hourly snapshots for the latest 48 hours, and daily snapshots for one or two months. Make sure to name the snapshots with data and time information.
- At least once a day, make sure to transfer an RDB snapshot outside your production environment. Cloud Storage is a good place to do so.
$ redis-cli BGSAVE$ gsutil cp dump.rdb gs://<your_bucket>/dump.$(date +%Y%m%d%H%M).rdb
To restore a data set from an RDB file, disable AOF and remove AOF and RDB before restoring data to Redis. Then you can copy RDB file from remote and simply restart redis-server to restore your data.
- Redis will try to restore data from the AOF file if AOF is enabled. If the AOF file cannot be found, Redis will start with an empty data set.
- Once the RDB snapshot is triggered due to the key changes, the original RDB file will be rewritten.
$ redis-cli CONFIG SET appendonly no$ redis-cli CONFIG REWRITE$ redis-cli SHUTDOWN$ rm *.aof *.rdb$ gsutil cp gs://<your_bucket>/dump.201812010000.rdb dump.rdb$ chown redis:redis dump.rdb$ redis-server redis-server.conf$ redis-cli CONFIG SET appendonly yes$ redis-cli CONFIG REWRITE
Redis on Compute Engine
You can also deploy your own open source Redis Cluster on Google Compute Engine if you want to use Redis Cluster, or want to read from replicas. The possible deployment options are:
- Run Redis on a Compute Engine instance–this is the simplest way to run the Redis service processes directly.
- Run Redis containers on Docker on a Compute Engine instance.
Pros of Redis on Compute Engine
-
You’ll have full control of Redis. You can configure, manage and operate as you like.
Cons of Redis on Compute Engine
- It’s not managed. You have to manage administrative tasks such as hardware provisioning, setup and configuration management, software patching, failover, backup and restore, configuration management, monitoring, etc.
- Availability, scalability and performance depend on how you architect. For example, a standalone setup is not ideal for production because it would be a single point of failure, so consider configuring master/slave replication to have redundant nodes with Sentinel, or set up a cluster.
- There’s a steeper learning curve: This option requires you to learn Redis itself in more detail.
For best results, run containers in host networking mode to eliminate additional network overhead from Docker networking. Make sure that you run one Redis container on each VM, otherwise it causes port conflicts. Limitations highly depend on how you design the cluster.
How to get started
Provision Compute Engine instances by deploying containers on VMs and managed instance groups. Alternatively, you can run your container on Compute Engine instances using whatever container technologies and orchestration tools that you need. You can create an instance from a public VM image and then install the container technologies that you want, such as Docker. Package service-specific components into separate containers and upload to Cloud Repositories.
The steps to configure Redis on Compute Engine instances are pretty basic if you’re already using Compute Engine, so we don’t describe them here. Check out the Compute Engine docs and open source Redis docs for more details.
Redis performance testing
It’s always necessary to measure the performance of your system to identify any bottlenecks before you expose it in production. The key factors affecting the performance of Redis are CPU, network bandwidth and latency, the size of the data set, and the operations you perform. If the result of the benchmark test doesn’t meet your requirements, consider scaling your infrastructure up or out or adjust the way you use Redis. There are a few ways to do benchmark testing against multiple Cloud Memorystore for Redis instances deployed using Twemproxy with an internal load balancer in front.
redis-benchmark
Redis-benchmark is an open source command line benchmark tool for Redis, which is included with the open source Redis package.
$ redis-benchmark -q -h 10.146.0.5 -p 26379 -c 100 -n 1000000 -k 1 -t set,get,mset,incr,lpush,lpop,sadd,spop,lpush,lrangeSET: 98318.76 requests per secondGET: 101833.00 requests per secondINCR: 102606.20 requests per secondLPUSH: 102954.80 requests per secondLPOP: 102606.20 requests per secondSADD: 102511.53 requests per secondSPOP: 105174.59 requests per secondLPUSH (needed to benchmark LRANGE): 102585.14 requests per secondLRANGE_100 (first 100 elements): 56299.97 requests per secondLRANGE_300 (first 300 elements): 20056.16 requests per secondLRANGE_500 (first 450 elements): 13864.24 requests per secondLRANGE_600 (first 600 elements): 10426.12 requests per secondMSET (10 keys): 82108.55 requests per second
memtier_benchmark
Memtier_benchmark is an open source command line benchmark tool for NoSQL key-value stores, developed by Redis Labs. It supports both Redis and Memcache protocols, and can generate various traffic patterns against instances.
$ memtier_benchmark --server=10.146.0.5 --port=26379 --protocol=redis --threads=2 --test-time=120 --ratio=1:1 --clients=50 --data-size=100 --key-pattern=S:S --pipeline=50ALL STATS========================================================================Type Ops/sec Hits/sec Misses/sec Latency KB/sec------------------------------------------------------------------------Sets 336058.83 --- --- 7.41600 48152.39Gets 336058.83 336058.83 0.00 7.41600 46511.48Waits 0.00 --- --- 0.00000 ---Totals 672117.65 336058.83 0.00 7.41600 94663.87
Migrating Redis to GCP
The most typical Redis customer journey to GCP we see is migration from other cloud providers. Here are a few options that can be used to perform data migration of Redis:
- Setting up the master/slave relationship to replicate the data
- Loading persistence data files [Use append-only file (AOF) or Redis database (RDB) to restore the data]
- Use MIGRATE command
- Use the redis-port tool developed by CodisLabs
If you would like to work with Google experts to migrate your Redis deployment onto GCP, get in touch and learn more here.